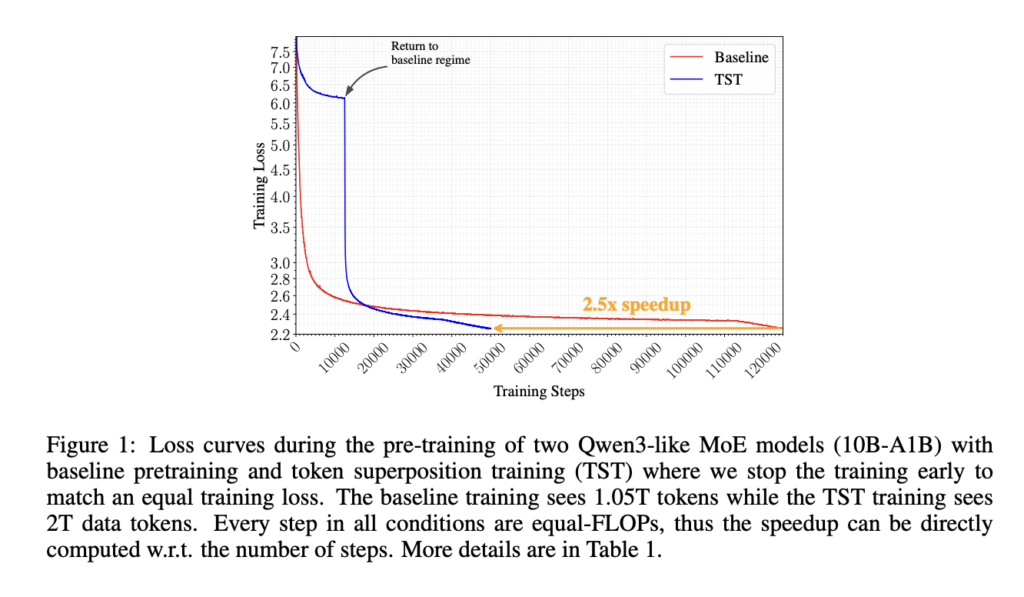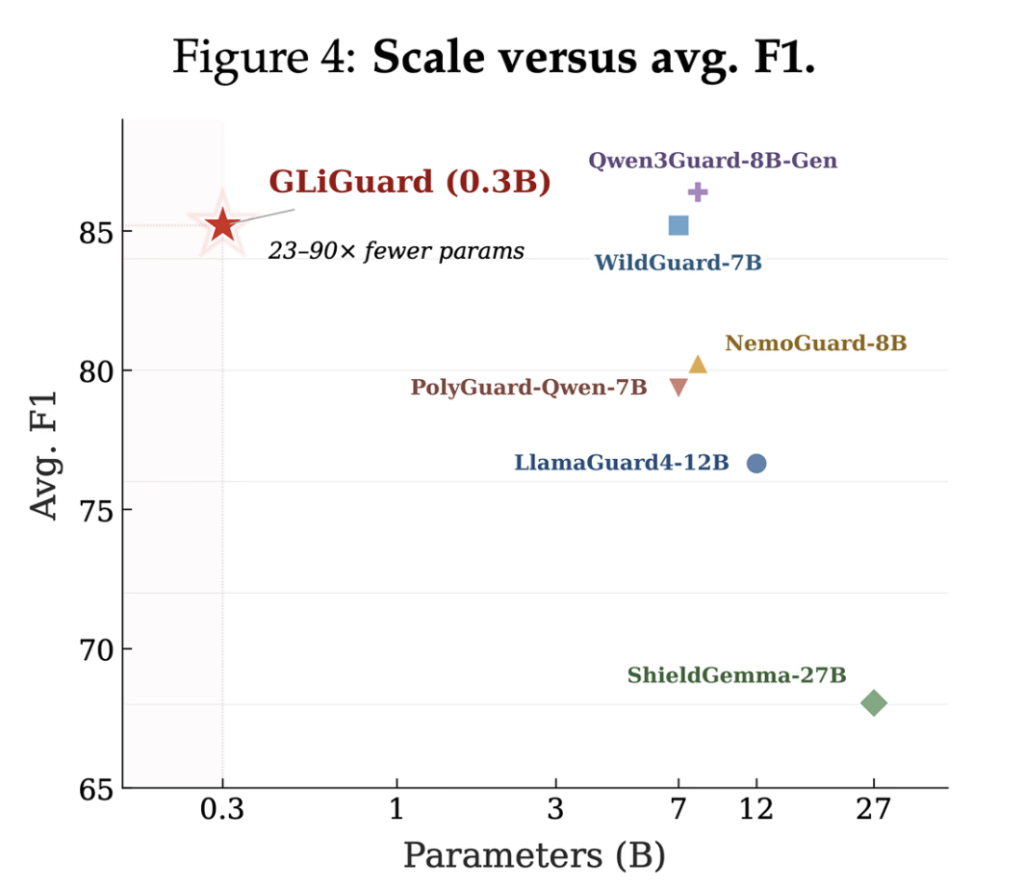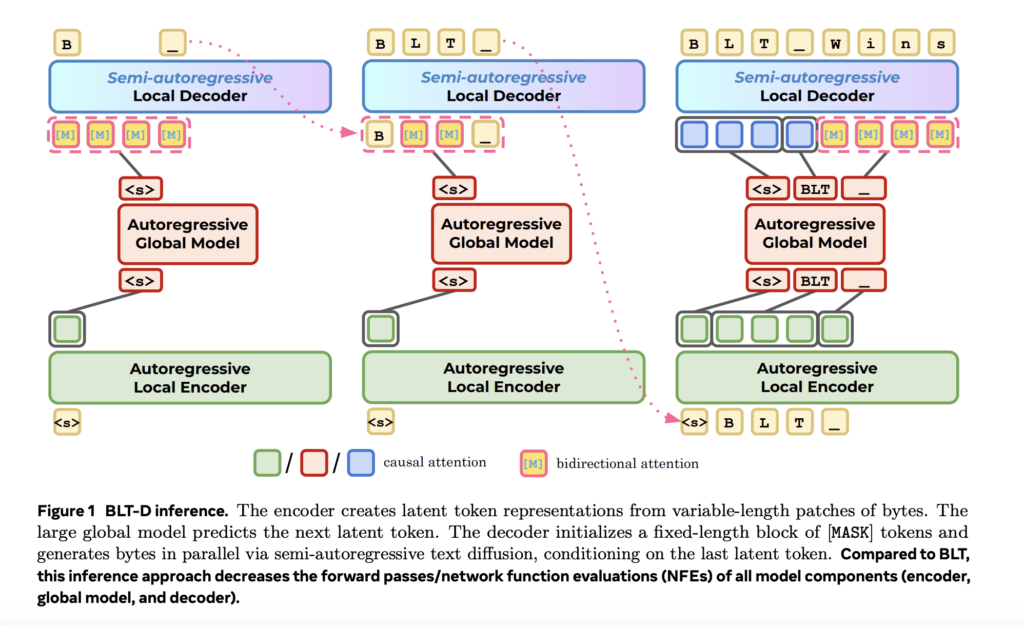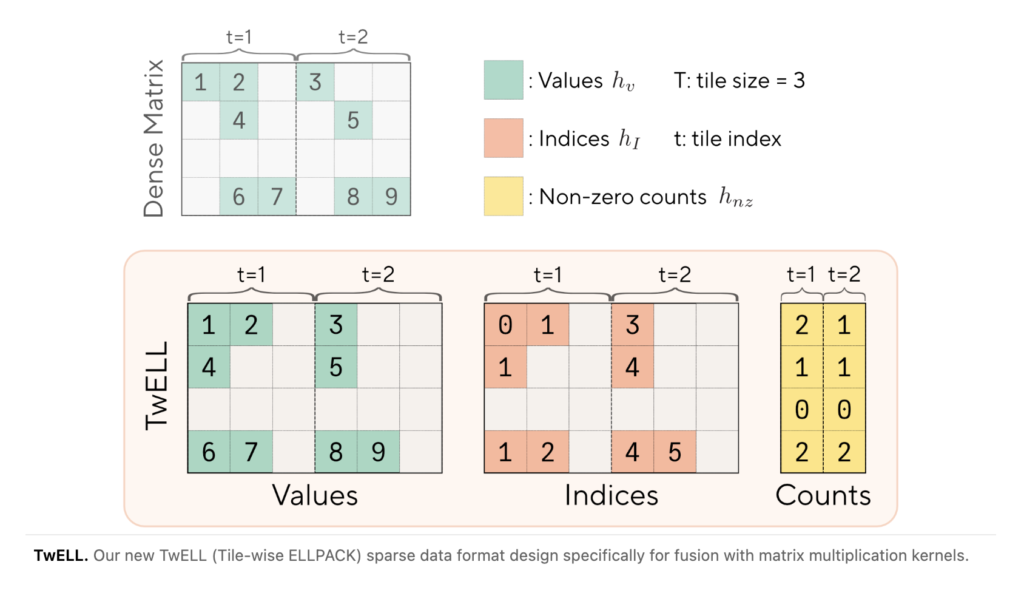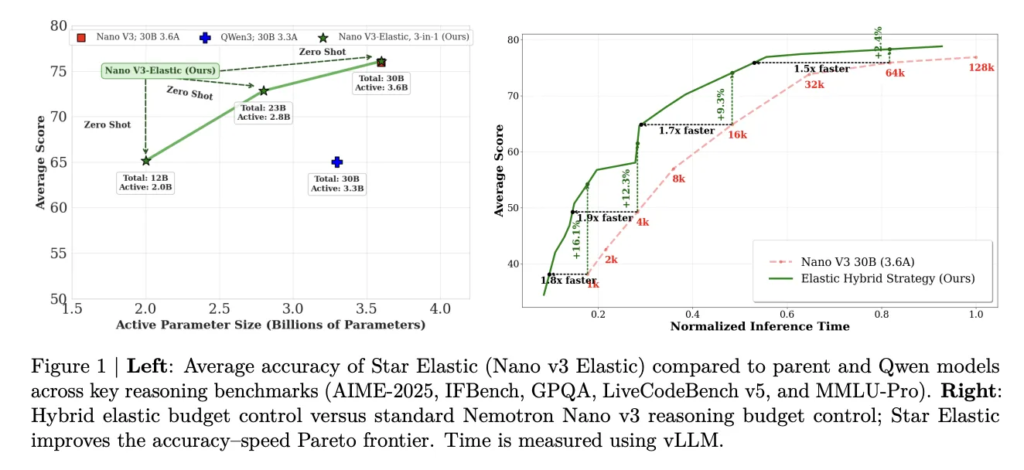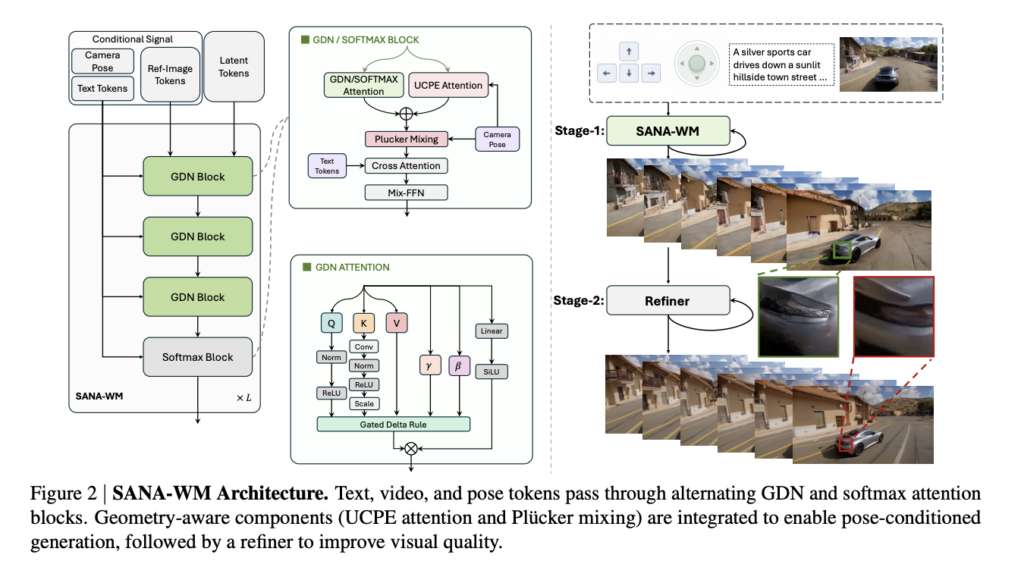
NVIDIA Introduces SANA-WM: A 2.6B-Parameter Open-Source World Model That Generates Minute-Scale 720p Video on a Single GPU
World models (systems that synthesize realistic video sequences from an initial image and a set of actions) are becoming central to embodied AI, simulation, and robotics research. The core challenge is scaling these systems to generate minute-long, high-resolution video without requiring prohibitively large clusters for both training and inference. Most competitive open-source baselines either require […]