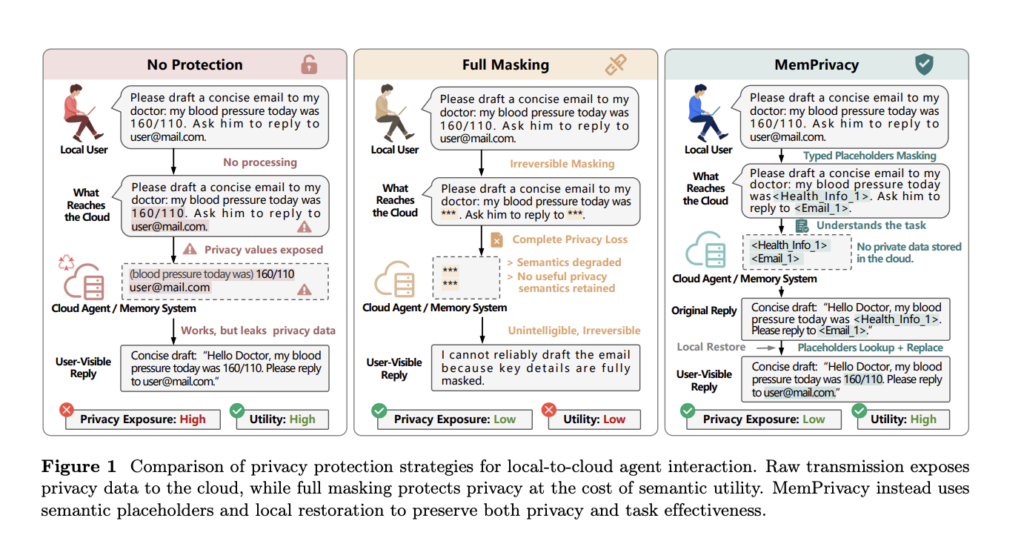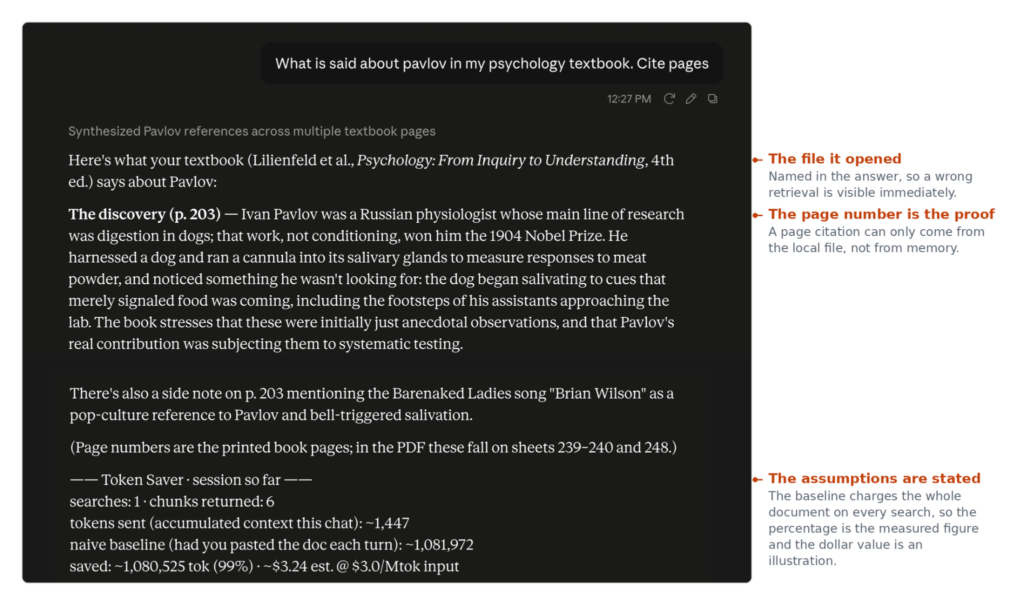
Meet Token Saver: An Open-Source MCP Extension Using Local Hybrid RAG to Cut Claude PDF Token Costs 90-99%
AI developers, researchers, and professionals frequently hit a frustrating wall when analyzing large documents with LLMs: the hidden, compounding cost of context windows. Pasting a 200-page PDF into a chat isn’t a one-time charge. Because the conversation history is re-sent to the model on every single turn, that massive document is paid for again with […]