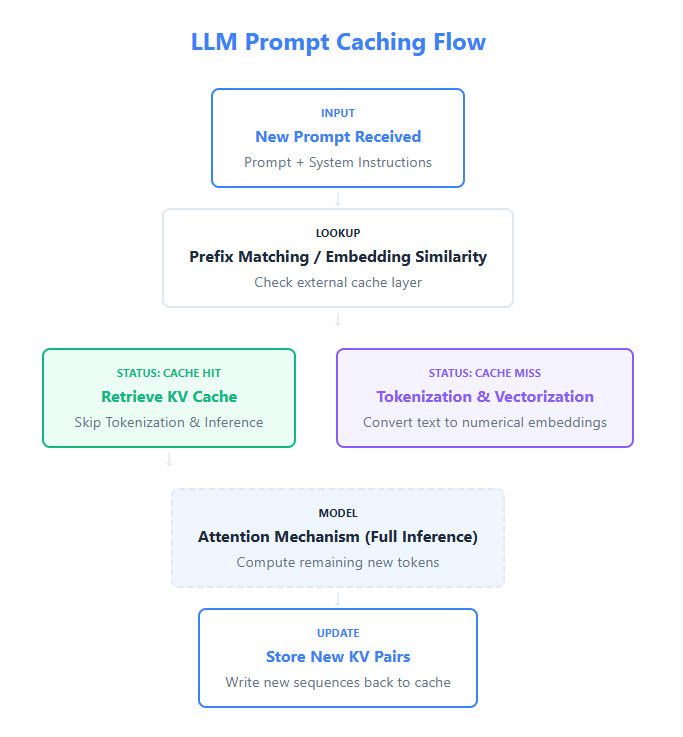
What are Context Graphs?
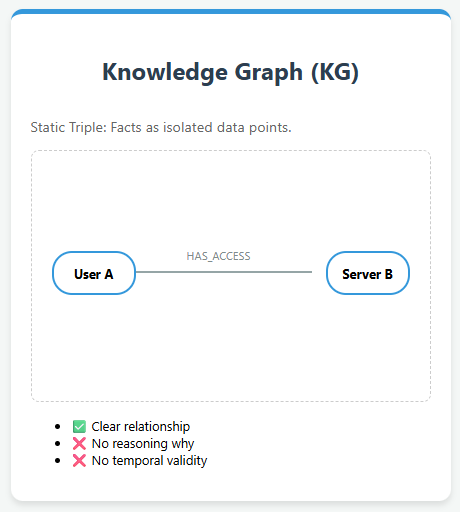
Knowledge Graphs and their limitations With the rapid growth of AI applications, Knowledge Graphs (KGs) have emerged as a foundational structure for representing knowledge in a machine-readable form. They organize information as triples—a head entity, a relation, and a tail entity—forming a graph-like structure where entities are nodes and relationships are edges. This representation allows […]