
AMD Releases Instella-MoE-16B-A3B: A Fully Open Mixture-of-Experts LLM With 2.8B Active Parameters Trained On Instinct GPUs
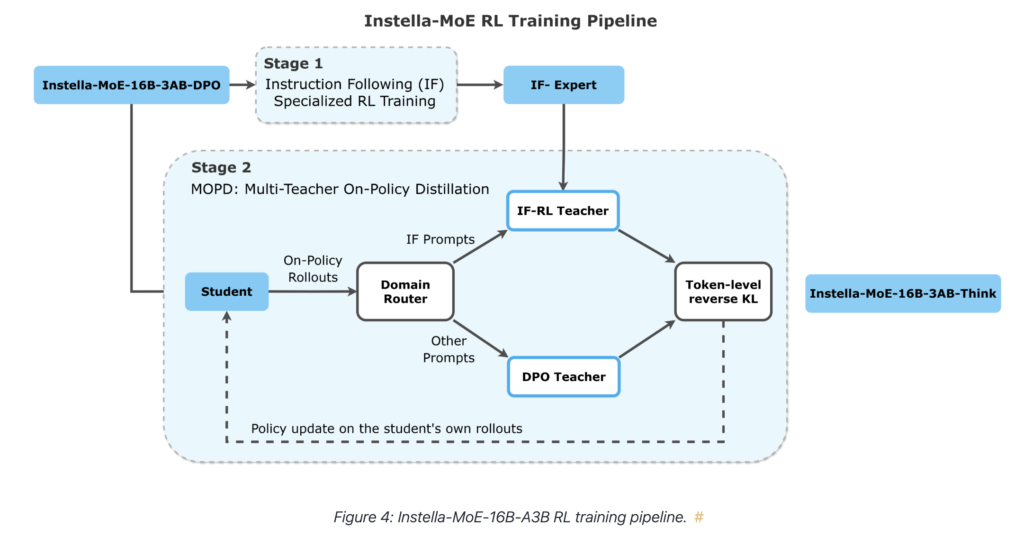
AMD released Instella-MoE-16B-A3B, a fully open Mixture-of-Experts language model trained from scratch on Instinct MI300X and MI325X GPUs. The model holds 16B total parameters but activates only 2.8B per token. AMD is publishing weights from every training stage, along with data mixtures, training configs, and inference code. Two systems-level choices carry the release: Gated Multi-head […]







