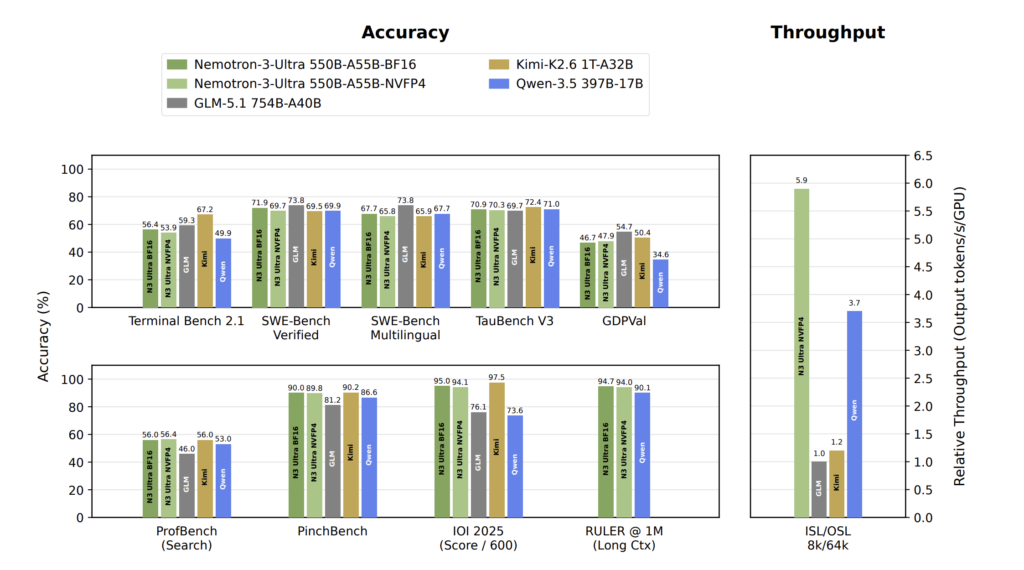
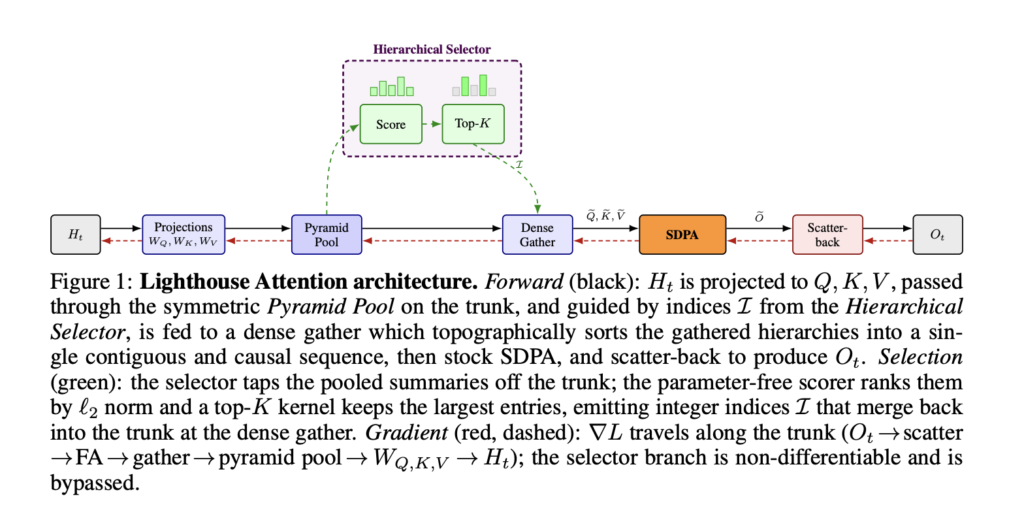
Google Cloud Introduces Open Knowledge Format (OKF): A Vendor-Neutral Markdown Spec for Giving AI Agents Curated Context
Foundation models keep getting stronger, yet they still stall on the same thing: context. A model can write code or analyze a dataset, but only with the right internal knowledge. That knowledge includes table schemas, metric definitions, runbooks, join paths and it lives scattered across catalogs, wikis, and a few senior engineers’ heads. Google Cloud […]