Miso Labs Releases MisoTTS: An 8B Emotive Text-to-Speech Model with Open Weights
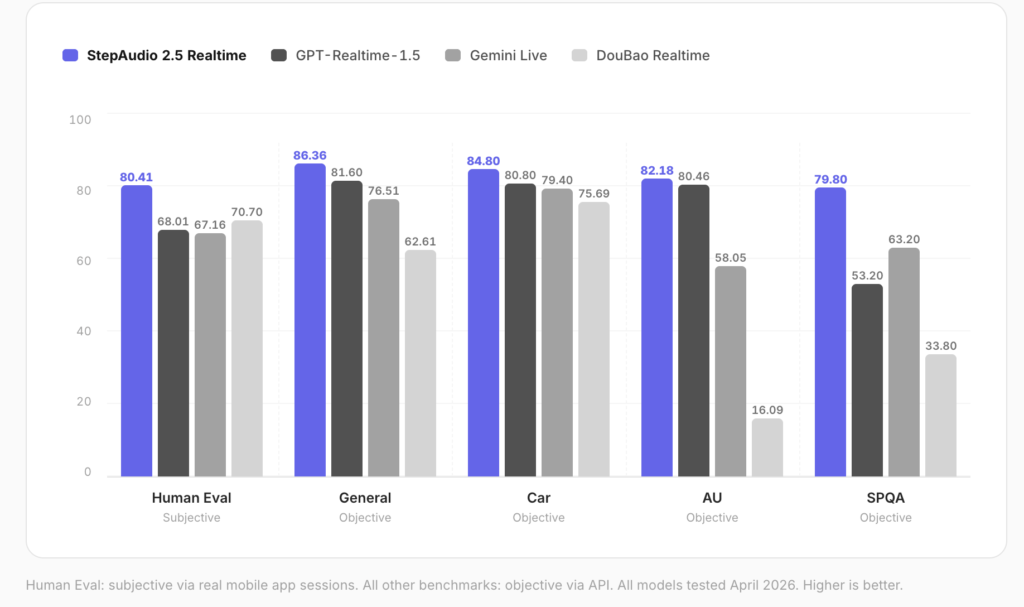
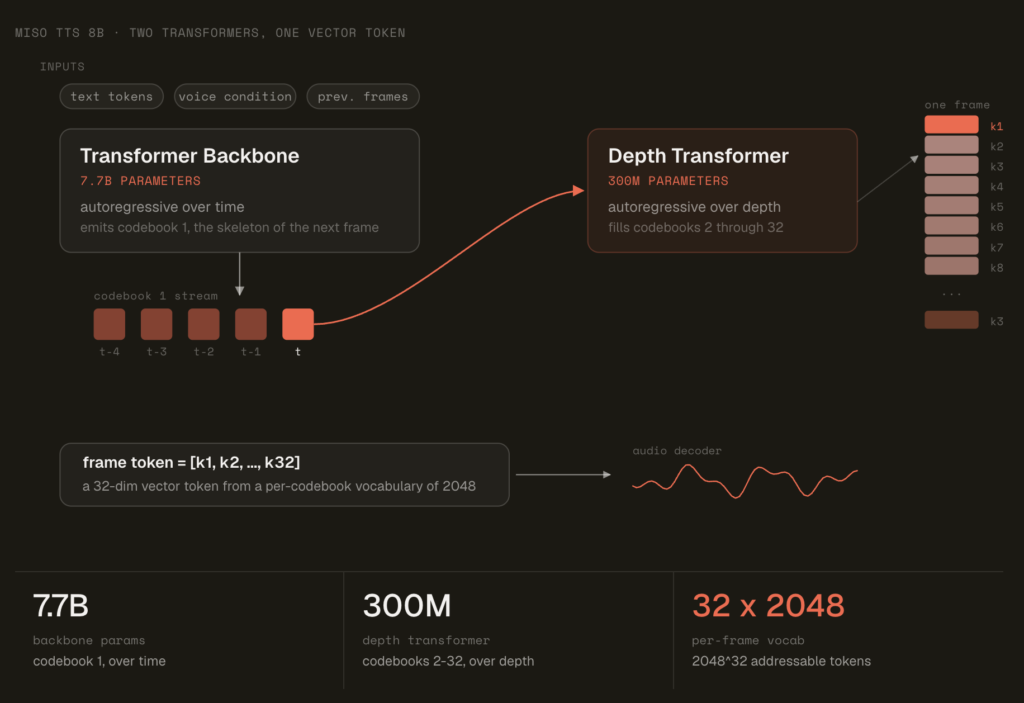
Miso Labs has released MisoTTS, an open-weights 8-billion-parameter text-to-speech model. It generates expressive speech from both text and audio context. The model uses residual vector quantization (RVQ) to widen its sonic range. This avoids scaling a single flat vocabulary while keeping parameter count fixed. What is MisoTTS MisoTTS is an 8B-parameter text-to-dialogue RVQ Transformer. It […]
Miso Labs Releases MisoTTS: An 8B Emotive Text-to-Speech Model with Open Weights Read More »