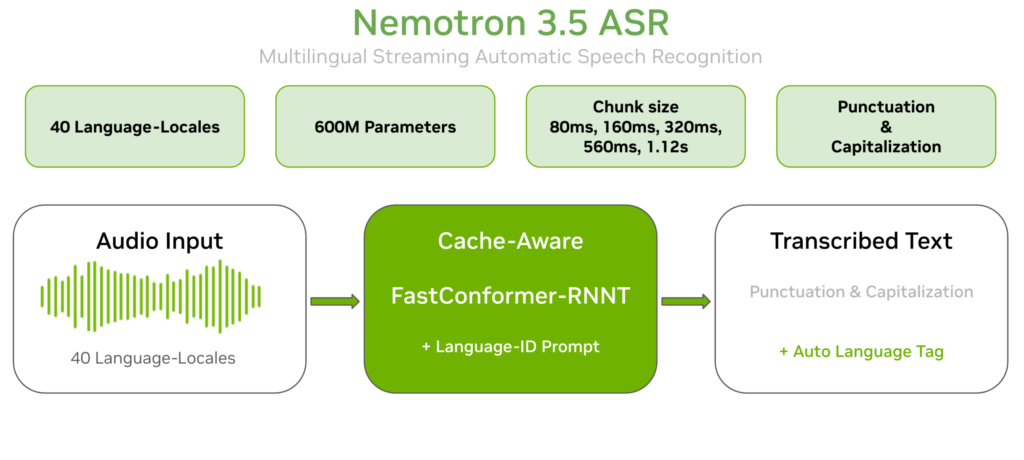
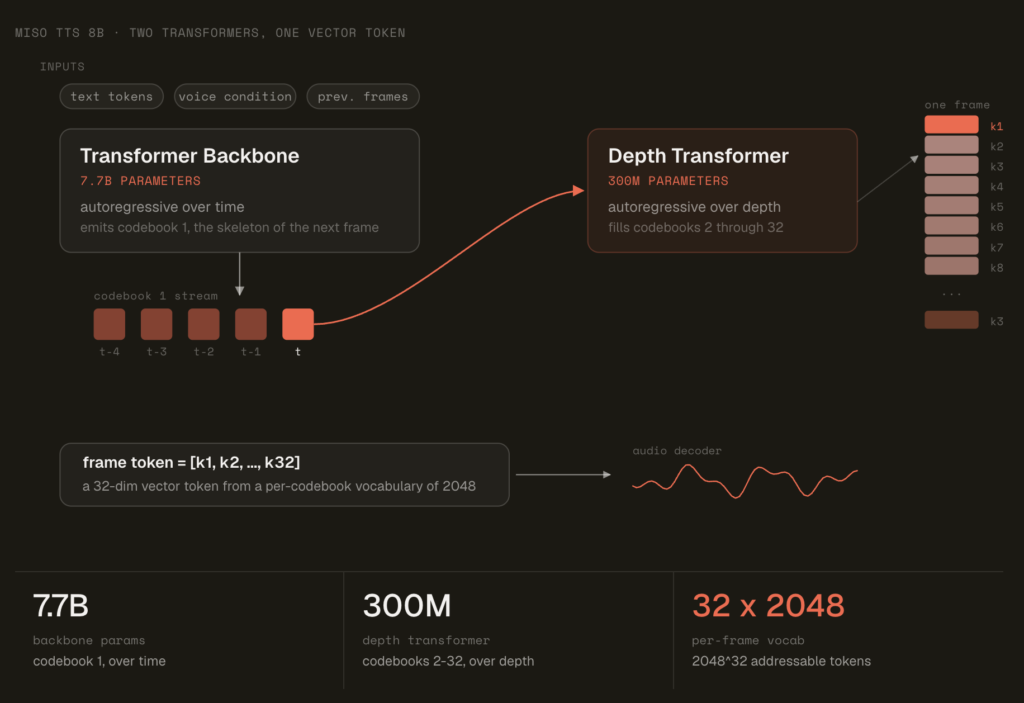
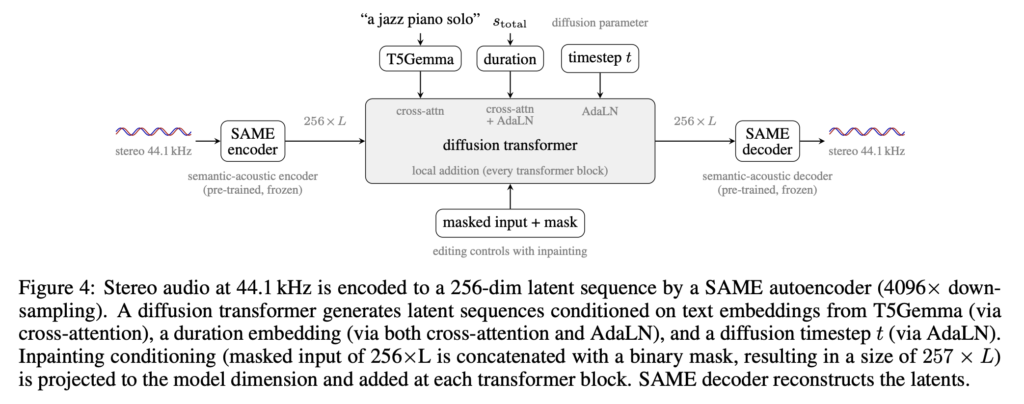
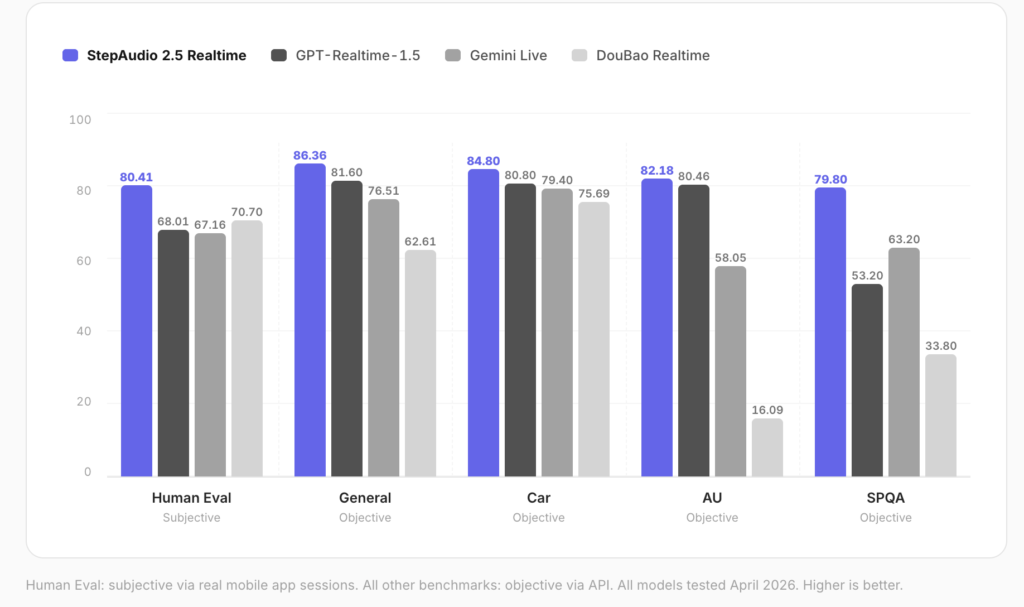
Gradium Launches stt-translate and s2s-translate, Real-Time Speech Translation Models Beating gpt-realtime-translate on Accuracy and Latency
Gradium today released two real-time speech translation models: stt-translate and s2s-translate. Both run across five languages and stream results live in the browser. Gradium claims a better accuracy-latency tradeoff than gpt-realtime-translate and gemini-3.5-live-translate. It also adds output voice control, including cloning, that gpt-realtime-translate lacks. TL;DR Gradium launched two real-time speech translation models: stt-translate (speech → […]