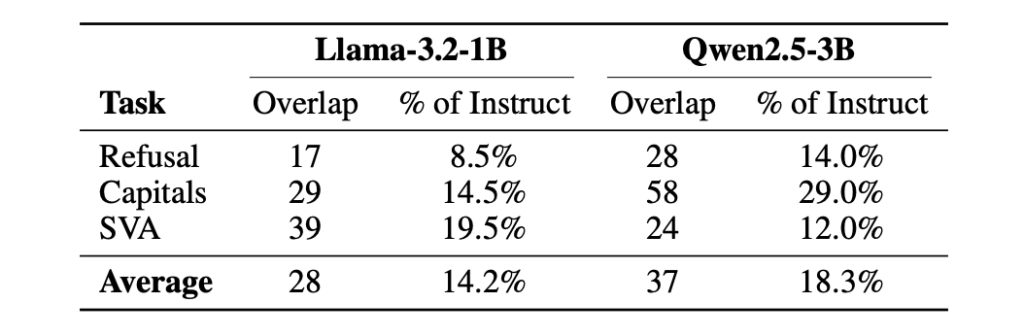
NVIDIA Introduces X-Token: Projection-Guided Cross-Tokenizer KD That Outperforms GOLD by +3.82 Average Points on Llama-3.2-1B
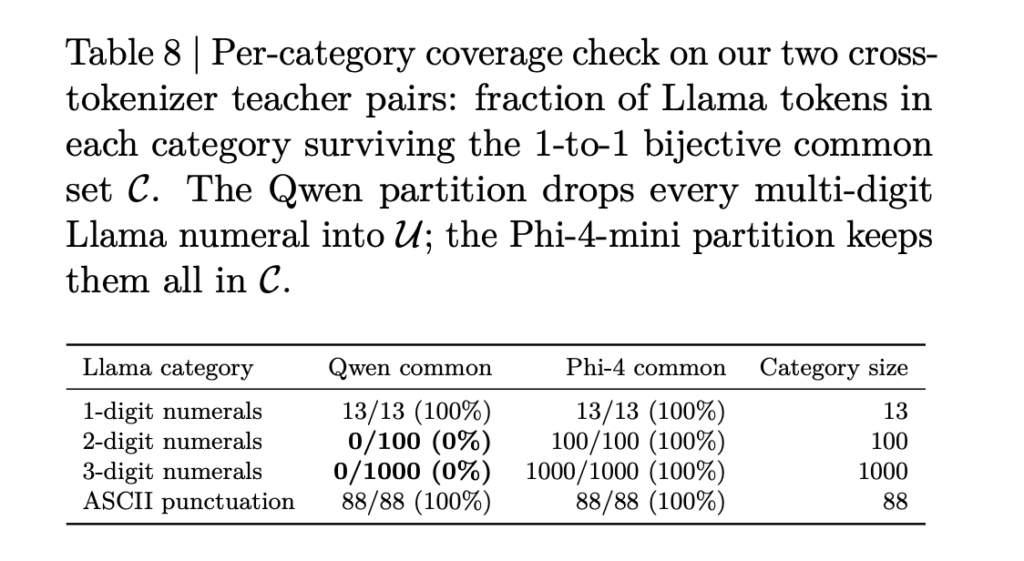
Knowledge distillation (KD) transfers “dark knowledge” from a large teacher model to a smaller student. The student learns from the teacher’s full output probability distribution over tokens, not just correct answers. This is done via per-position Kullback–Leibler (KL) divergence over next-token probability distributions. This formulation requires a shared tokenizer. A practitioner committed to Llama-3.2-1B cannot […]