Meet AntAngelMed: A 103B-Parameter Open-Source Medical Language Model Built on a 1/32 Activation-Ratio MoE Architecture
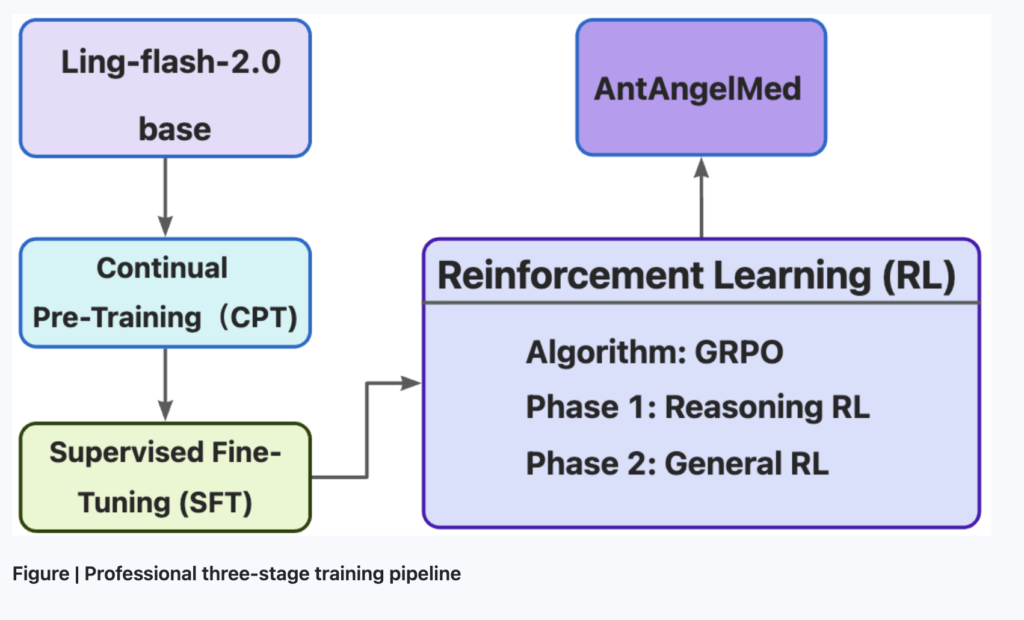
A team researchers from China have released AntAngelMed, a large open-source medical language model that the team describes as the largest and most capable of its kind currently available. What Is AntAngelMed? AntAngelMed is a medical-domain language model with 103 billion total parameters, but it does not activate all of those parameters during inference. Instead, […]