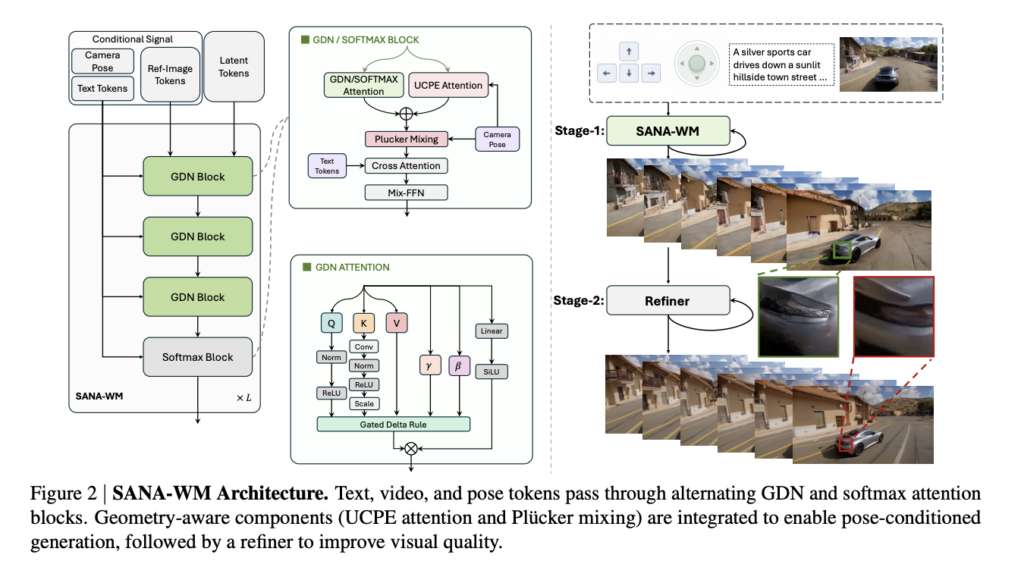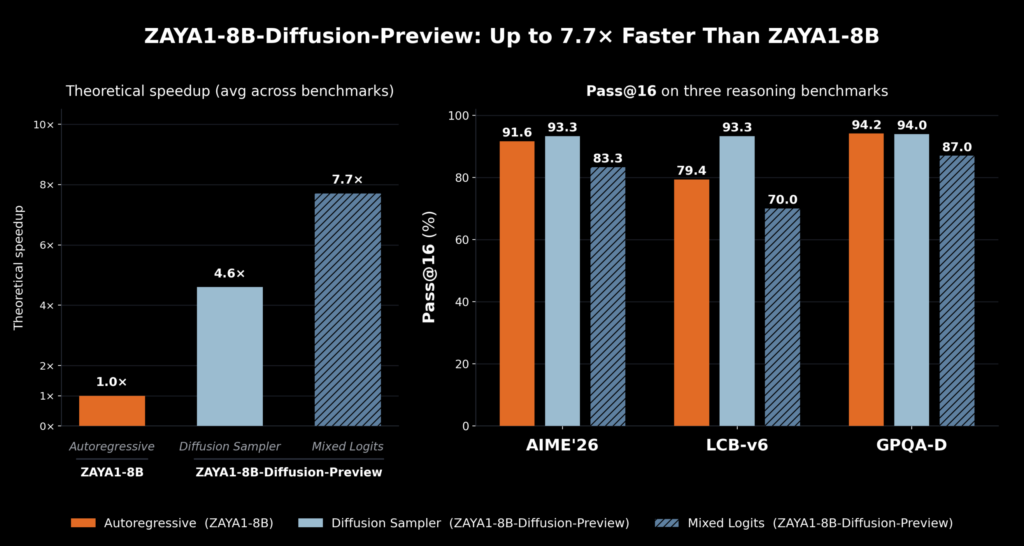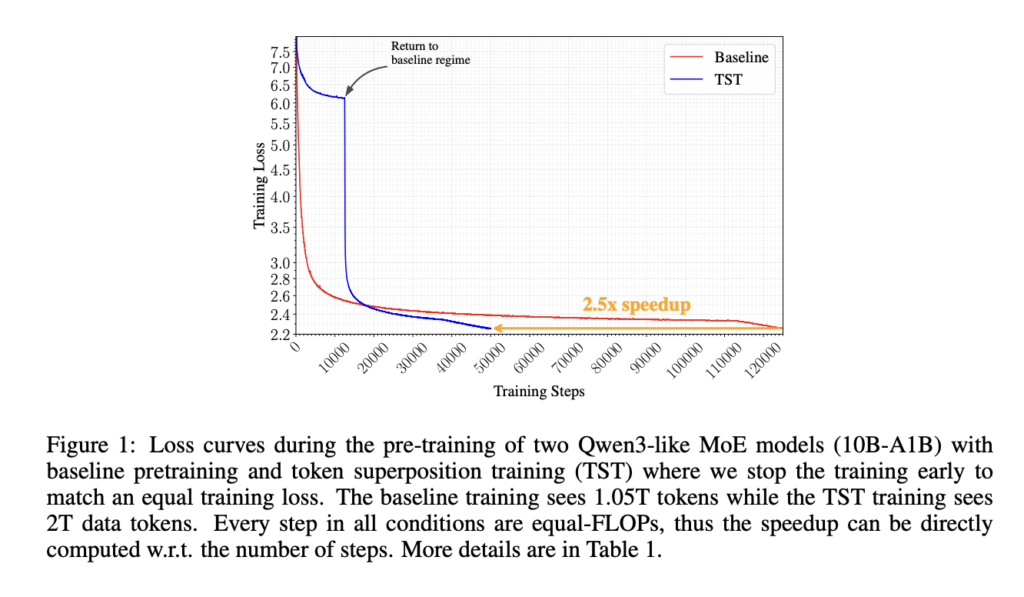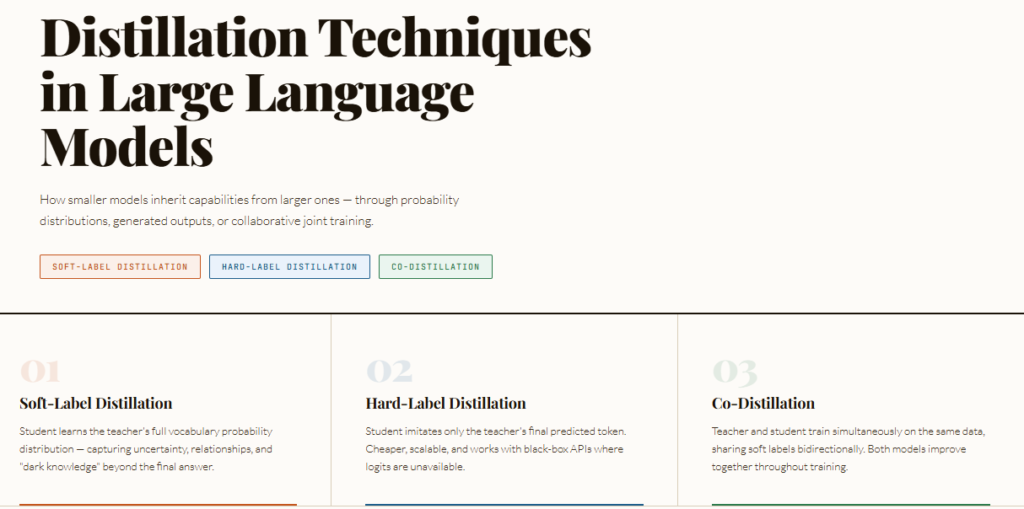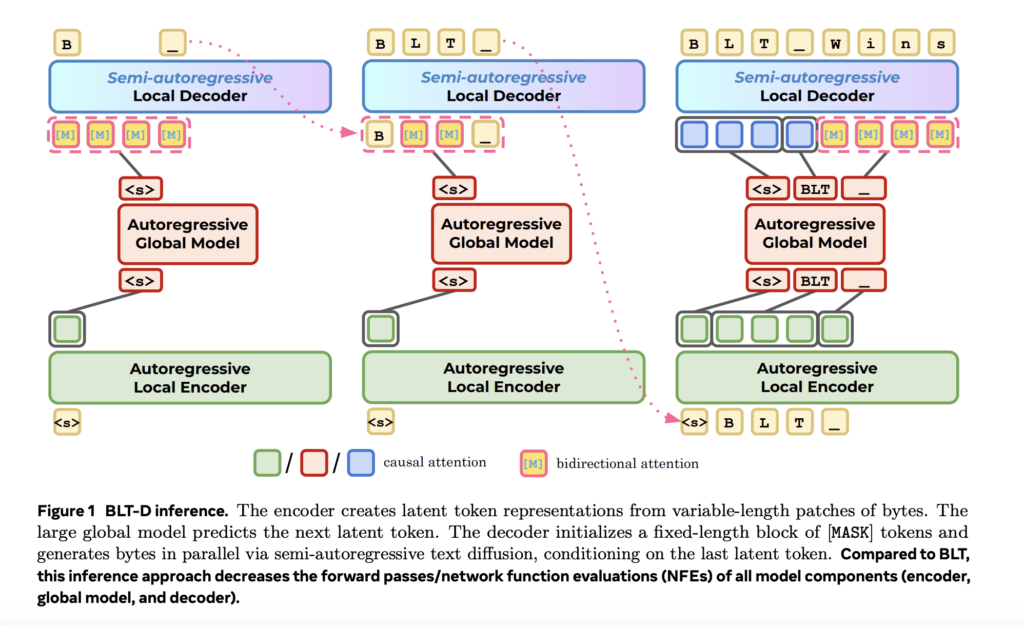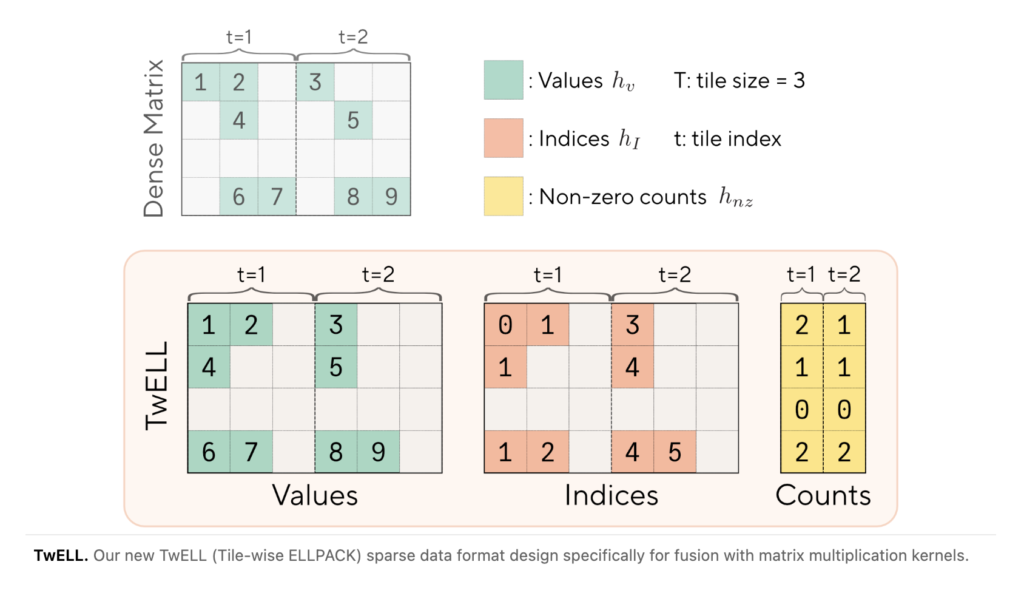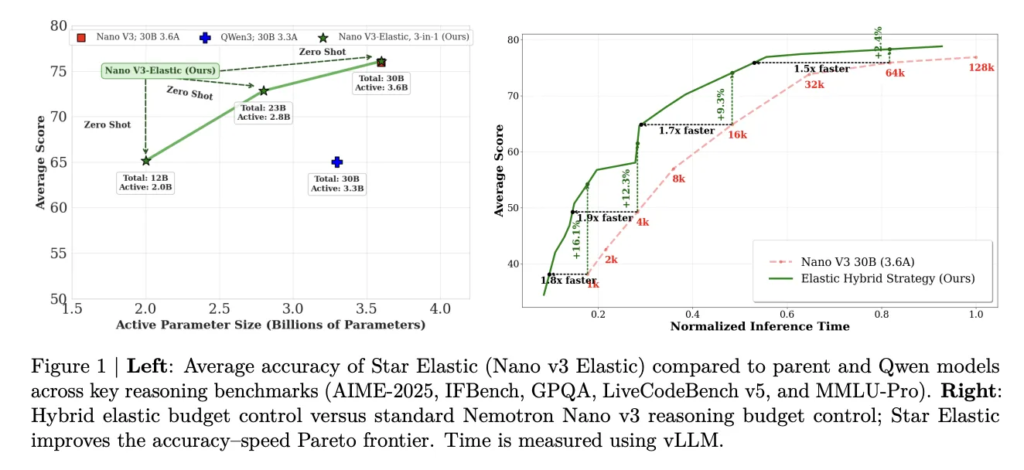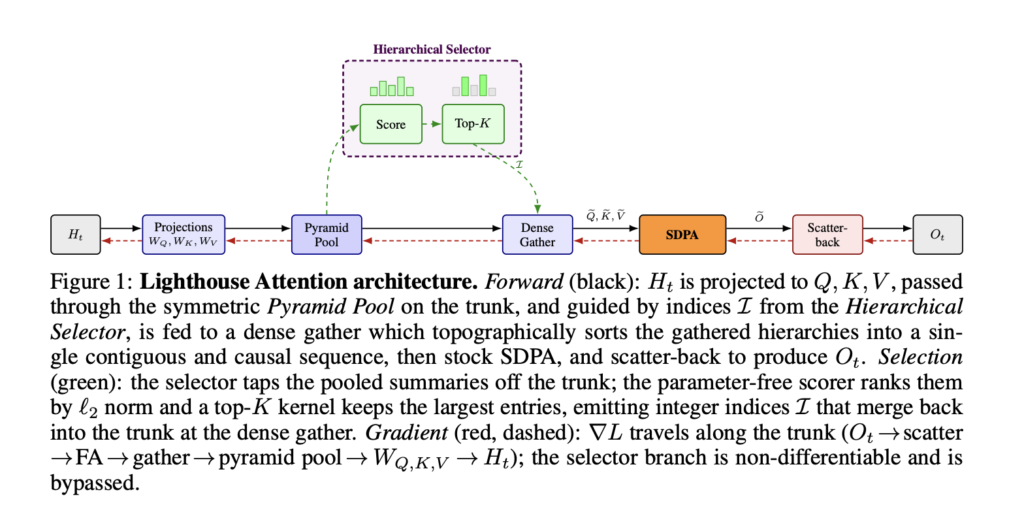
Nous Research Proposes Lighthouse Attention: A Training-Only Selection-Based Hierarchical Attention That Delivers 1.4–1.7× Pretraining Speedup at Long Context
Training large language models on long sequences has a well-known problem: attention is expensive. The scaled dot-product attention (SDPA) at the core of every transformer scales quadratically Θ(N²) in both compute and memory with sequence length N. FlashAttention addressed this through IO-aware tiling that avoids materializing the full N×N attention matrix in high-bandwidth memory, reducing […]