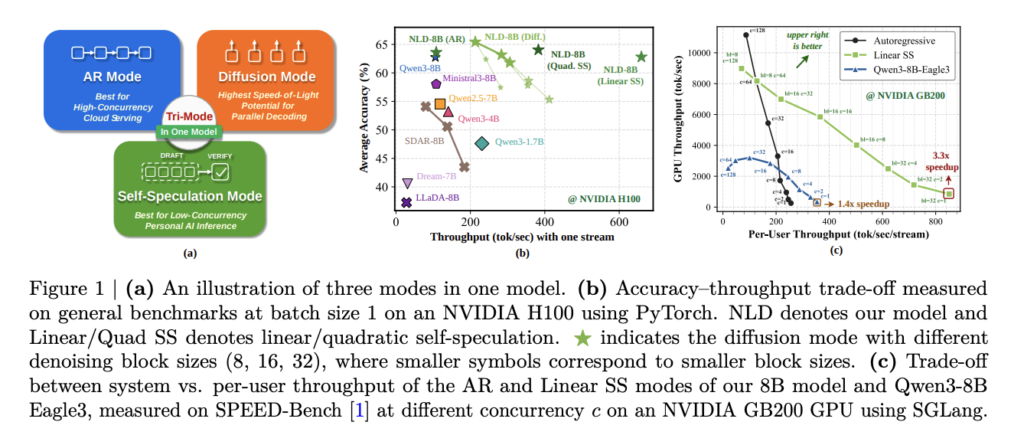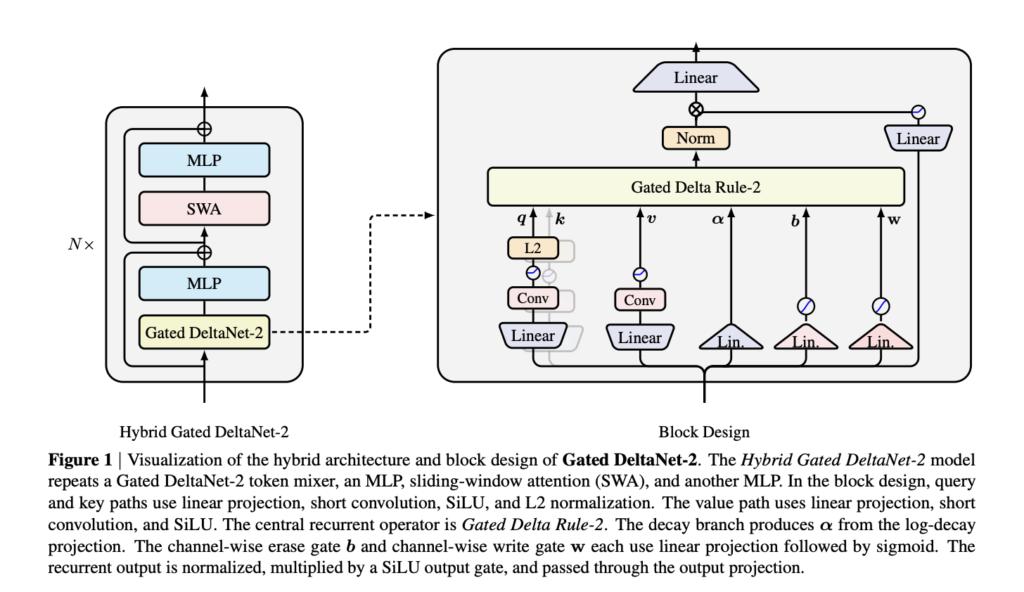
NVIDIA AI Releases Gated DeltaNet-2: A Linear Attention Layer That Decouples Erase and Write in the Delta Rule
Linear attention replaces the unbounded KV cache of softmax attention with a fixed-size recurrent state. This cuts sequence mixing to linear time and decoding to constant memory. The hard part is not what to forget. It is how to edit a compressed memory without scrambling existing associations. NVIDIA has released Gated DeltaNet-2, a linear attention […]