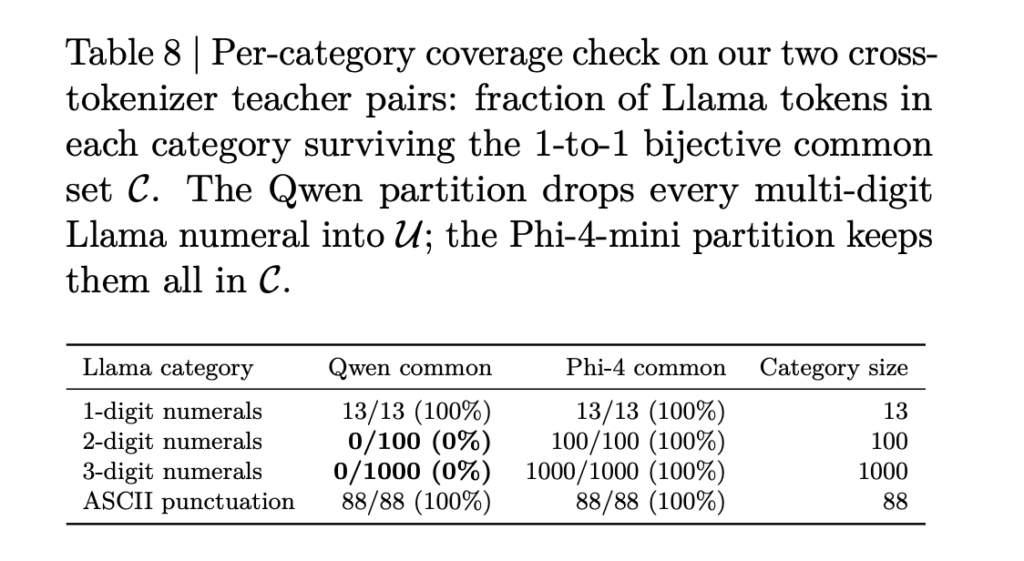
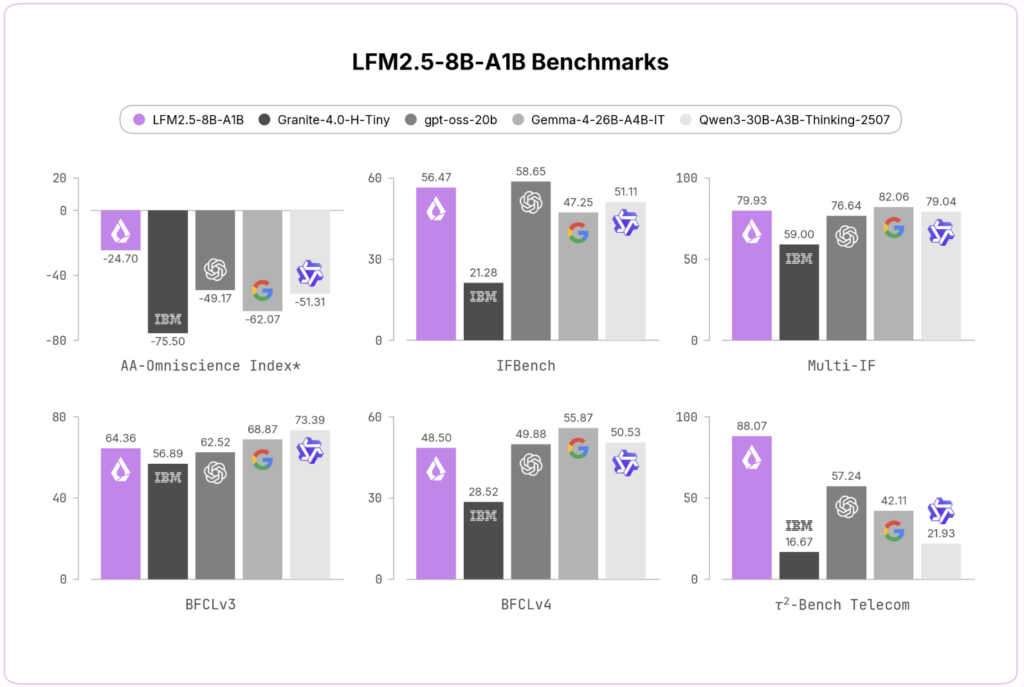
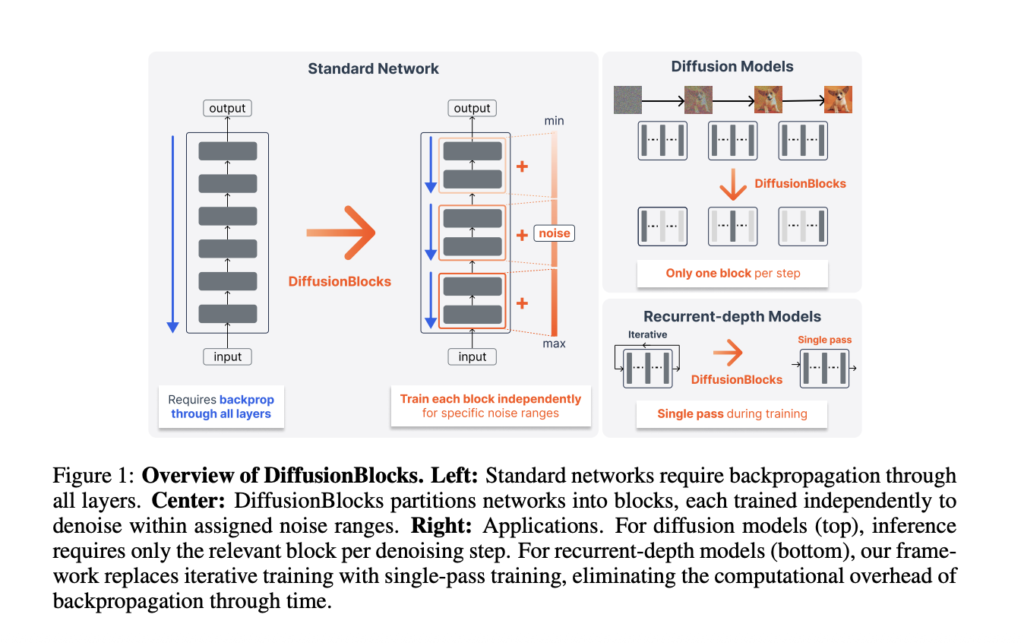
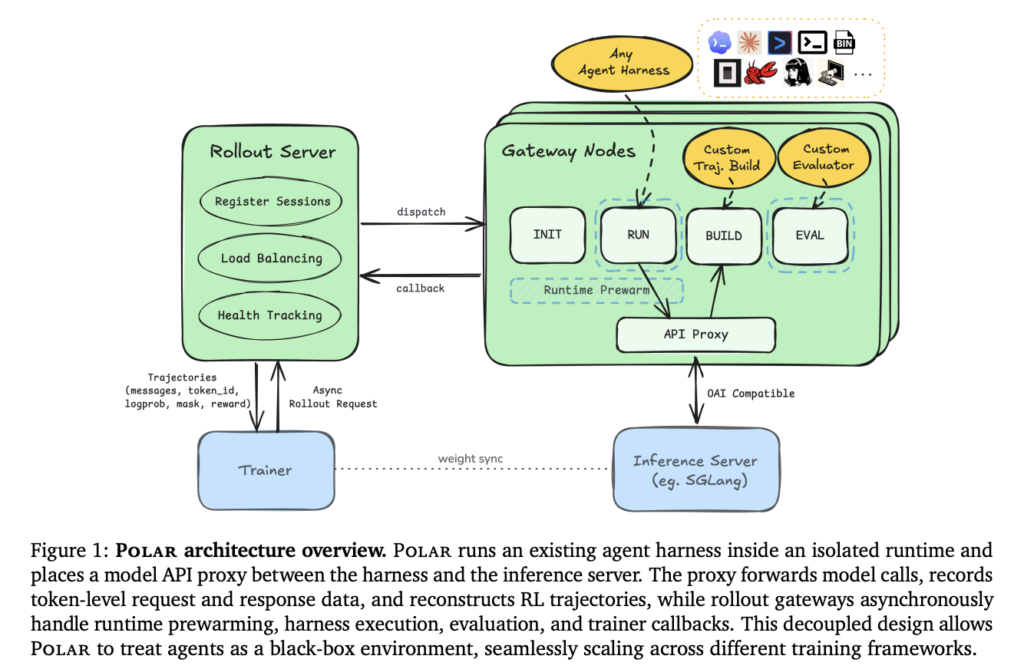
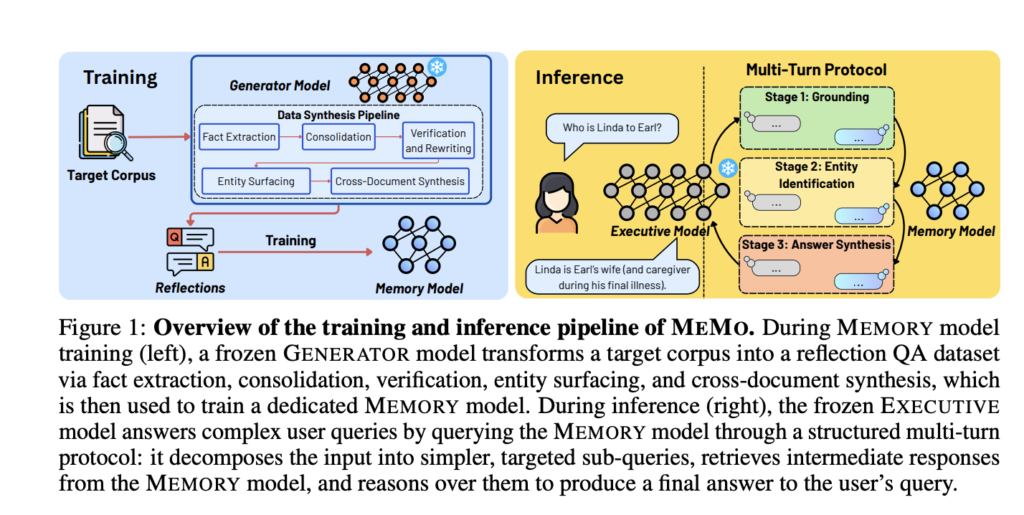
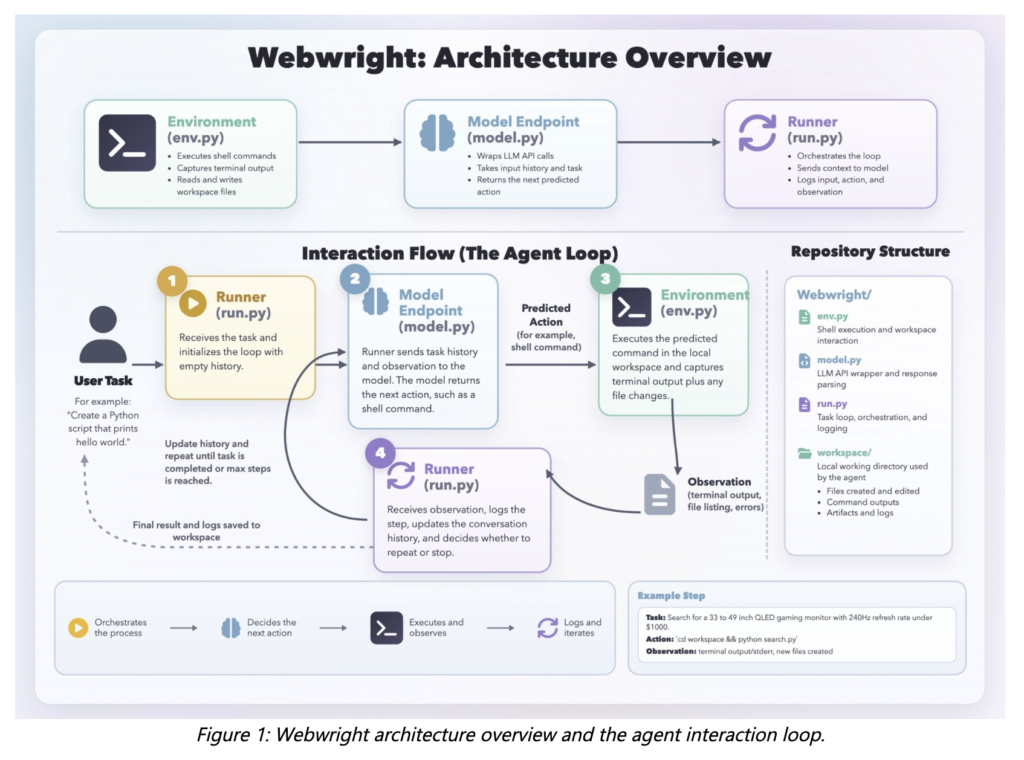
Trajectory Releases a Concurrent Multi-LoRA Training Stack for Continual Learning, Reporting a 2.81× Experiment-Throughput Gain
Trajectory’s concurrent multi-LoRA stack reports a 2.81× experiment-throughput gain over single-tenant RL, with all code in the NovaSky-AI/SkyRL GitHub repository. Most language models improve in discontinuous jumps. A team collects data, trains, and ships a new version. This takes months and produces remarkable or catastrophic behavior for users. Trajectory wants to replace that cycle with […]