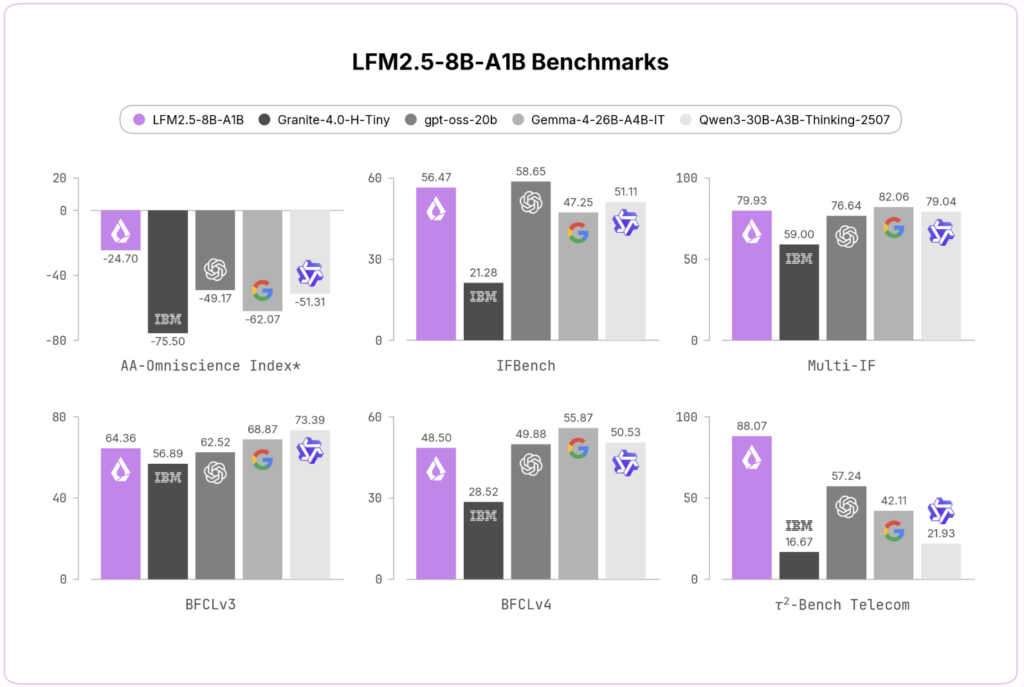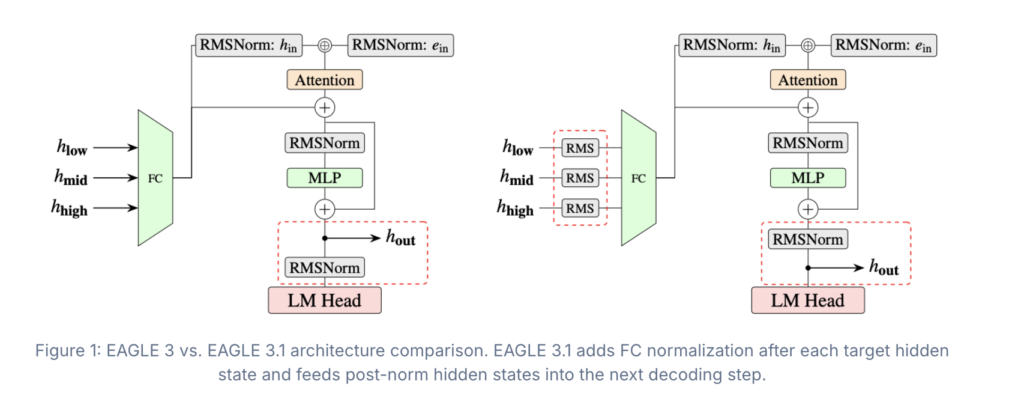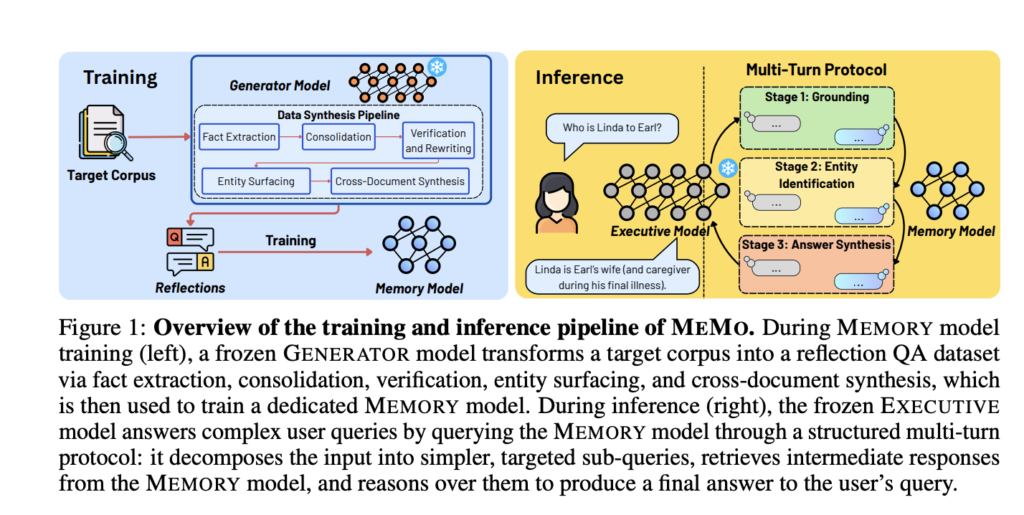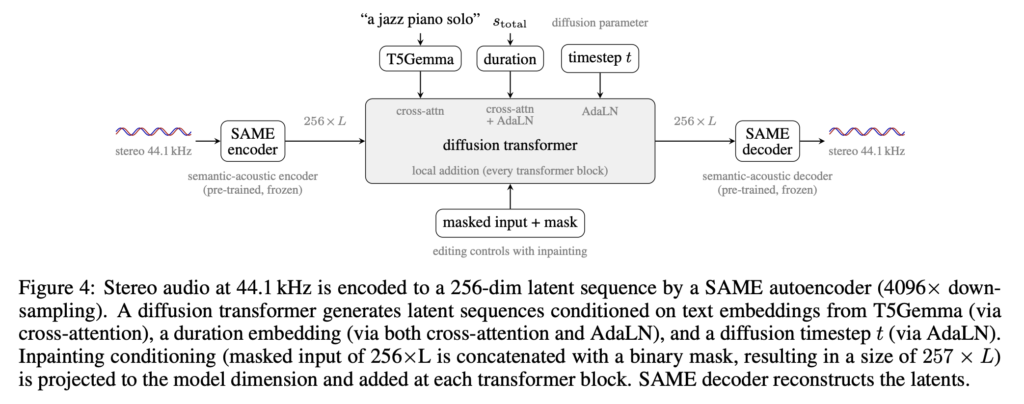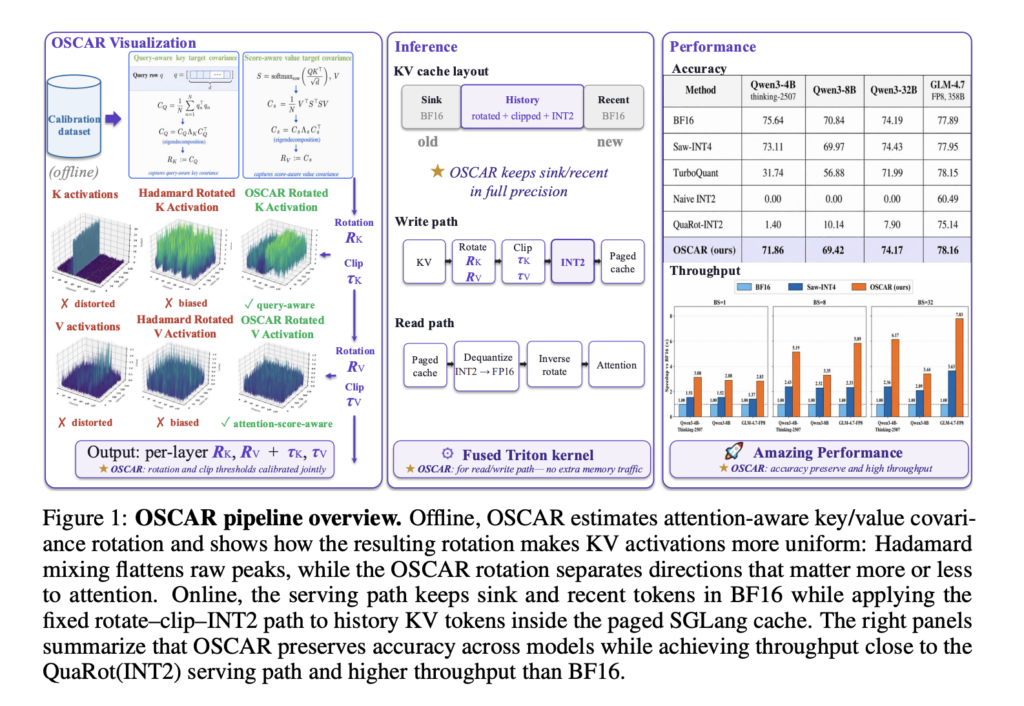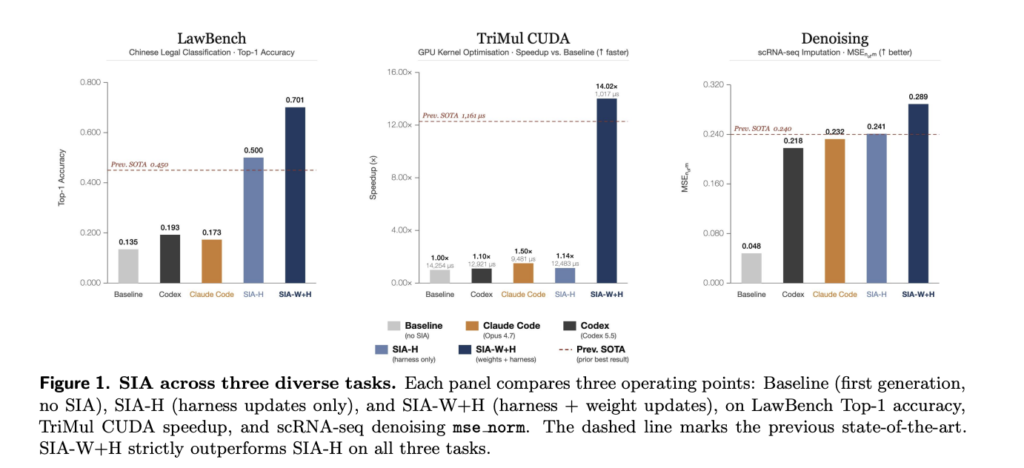
Hexo Labs Open-Sources SIA: A Self-Improving Agent That Updates Both the Harness and the Model Weights
Most AI agents stop improving once a human stops tuning them. The model is fixed. The scaffold around it is fixed. Hexo Labs wants to move both at once. It released SIA (Self-Improving AI) this week as an open-source framework under an MIT license. The core claim of this research is narrow but concrete. SIA […]