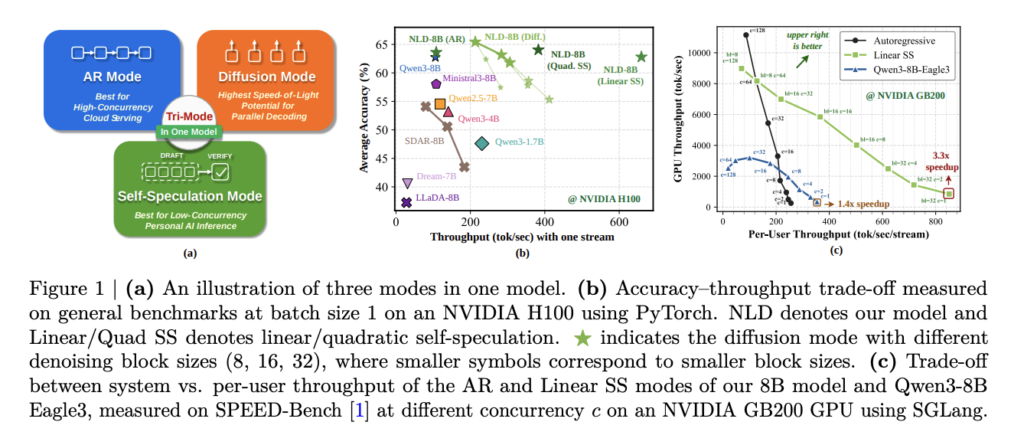
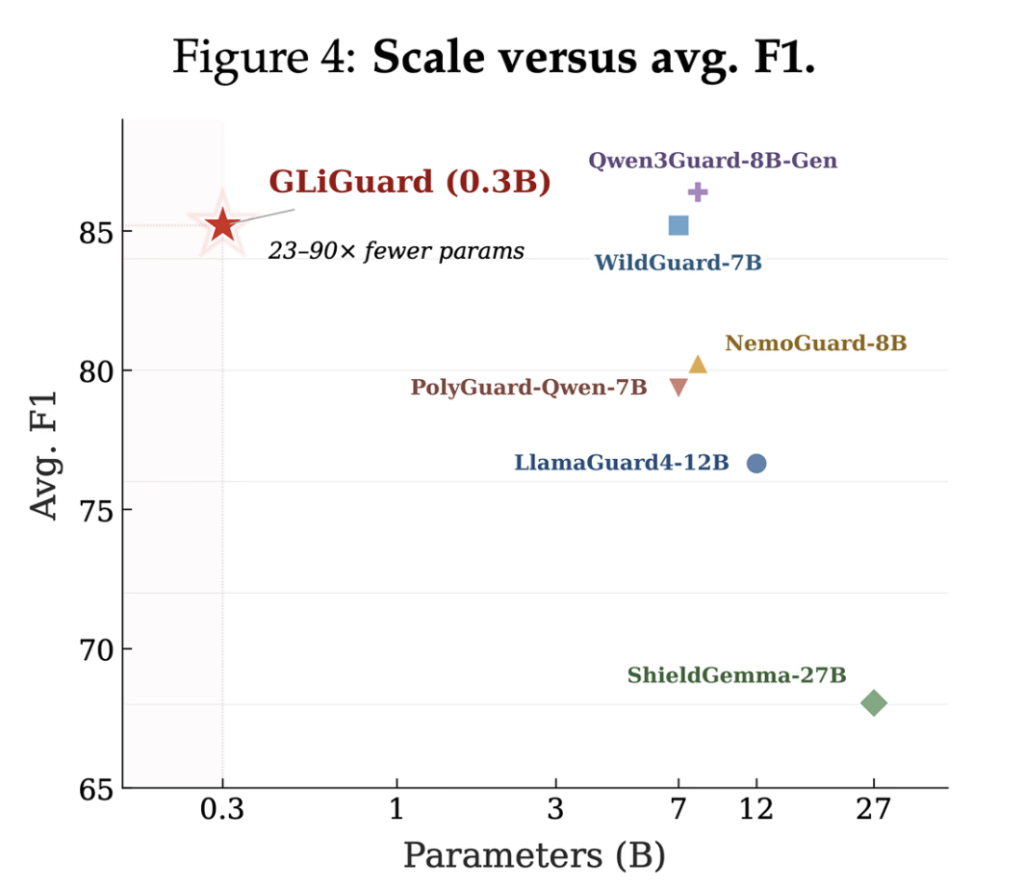
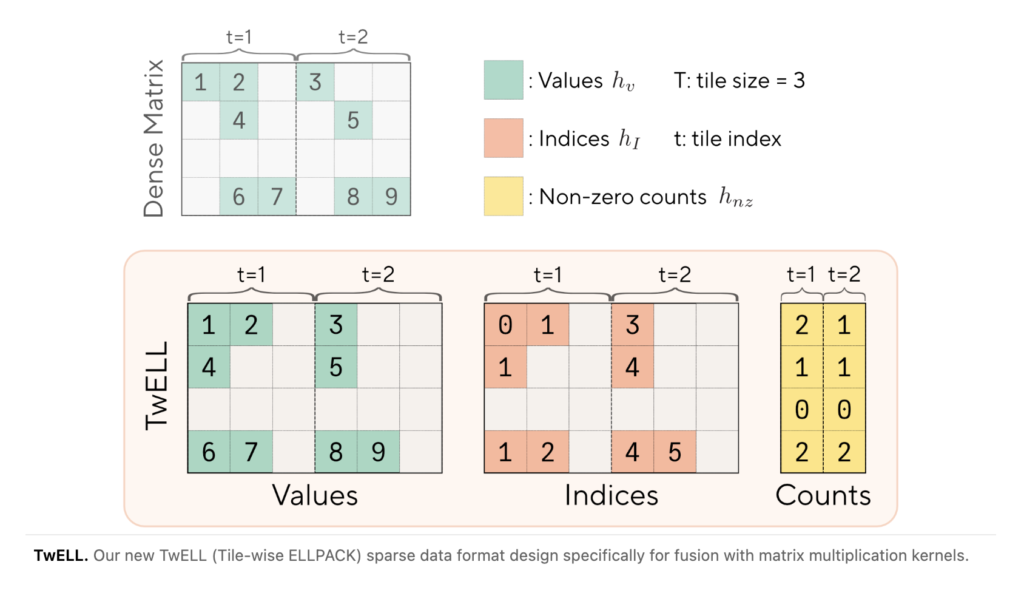
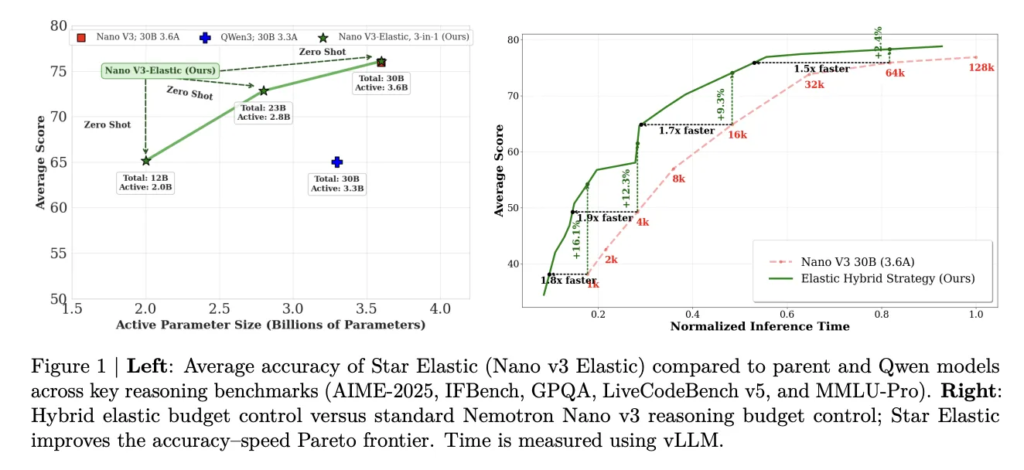
Meet Turbovec: A Rust Vector Index with Python Bindings, and Built on Google’s TurboQuant Algorithm
Vector search underpins most retrieval-augmented generation (RAG) pipelines. At scale, it gets expensive. Storing 10 million document embeddings in float32 consumes 31 GB of RAM. For dev teams running local or on-premise inference, that number creates real constraints. A new open-source library called turbovec addresses this directly. It is a vector index written in Rust […]