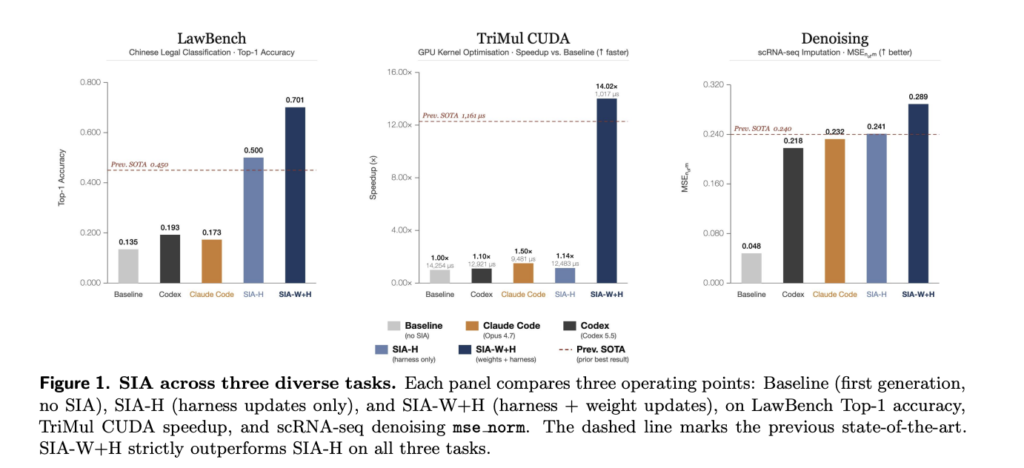
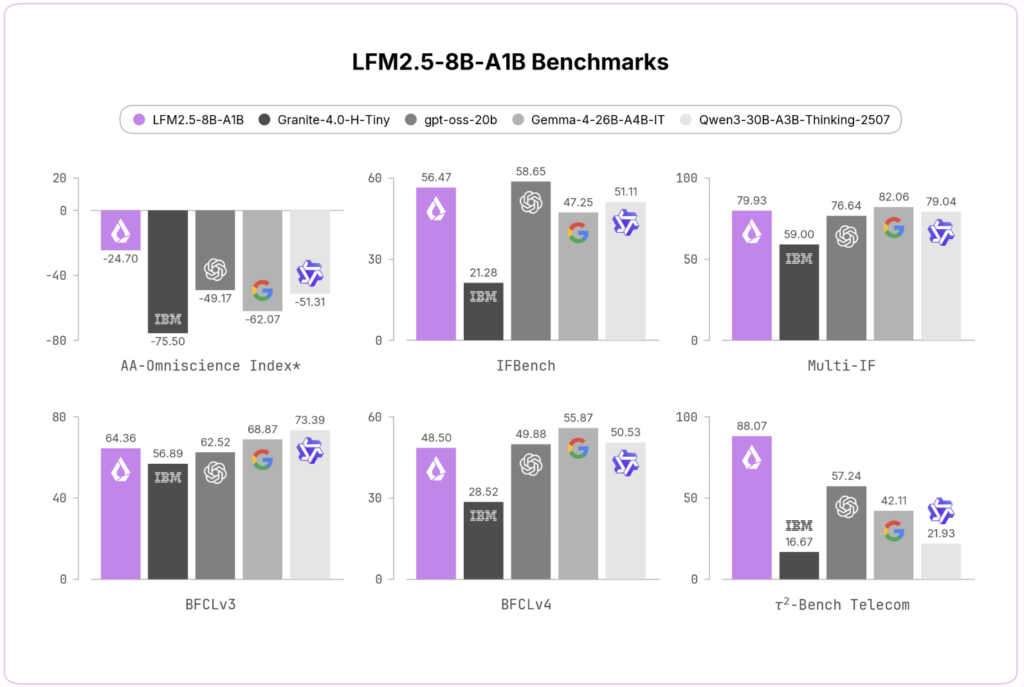
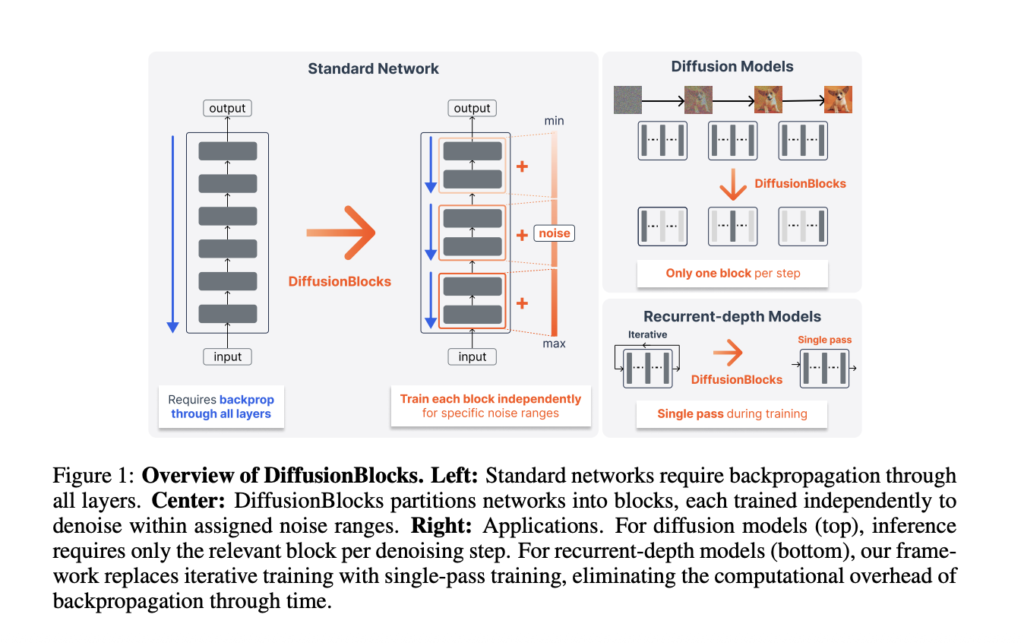
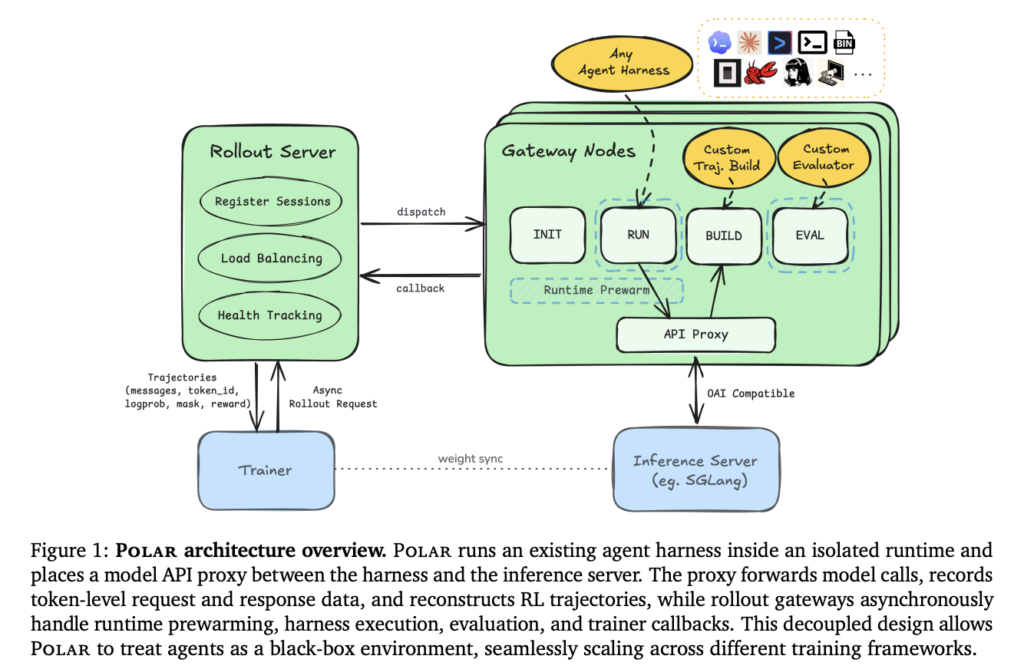
Meet mKernel: A Multi-GPU, Multi-Node Fused Kernel Library for GPU-Driven Communication
GPU communication overhead is a measurable bottleneck in production AI workloads. According to data cited by the mKernel project, communication can consume 43.6% of the forward pass and 32% of end-to-end training time. Across popular Mixture-of-Experts (MoE) models, inter-device communication can account for up to 47% of total execution time. Researchers from UC Berkeley’s UCCL […]
Meet mKernel: A Multi-GPU, Multi-Node Fused Kernel Library for GPU-Driven Communication Read More »