NVIDIA AI Introduce SpatialClaw: A Training-Free Agent That Treats Code as the Action Interface for Spatial Reasoning
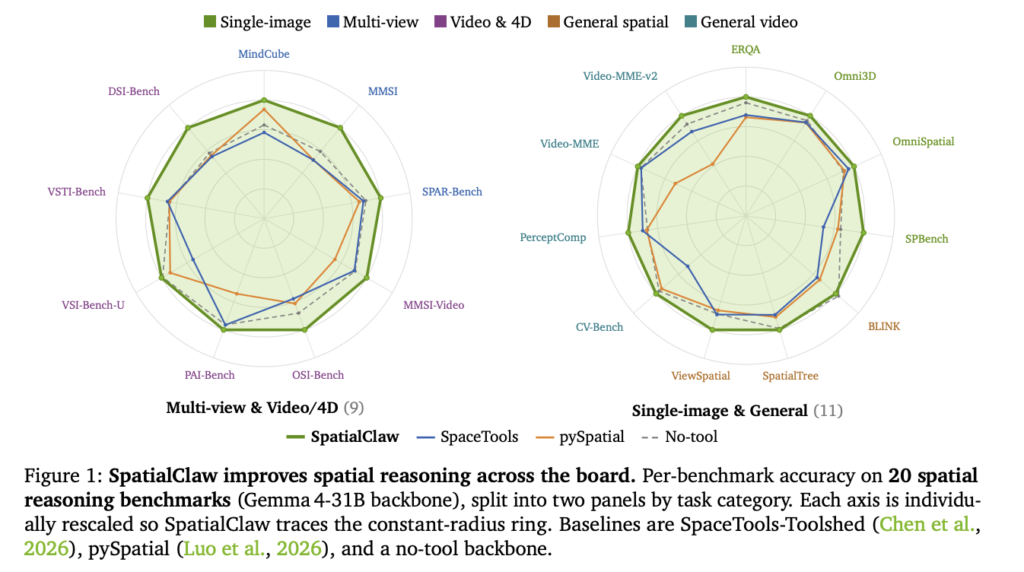
NVIDIA Research has released SpatialClaw, a training-free framework for spatial reasoning. It targets a persistent weakness in vision-language models (VLMs). These models still struggle to judge where objects are, how they relate, and how they move in 3D. SpatialClaw does not retrain the model. Instead, it changes the action interface the agent uses to call […]