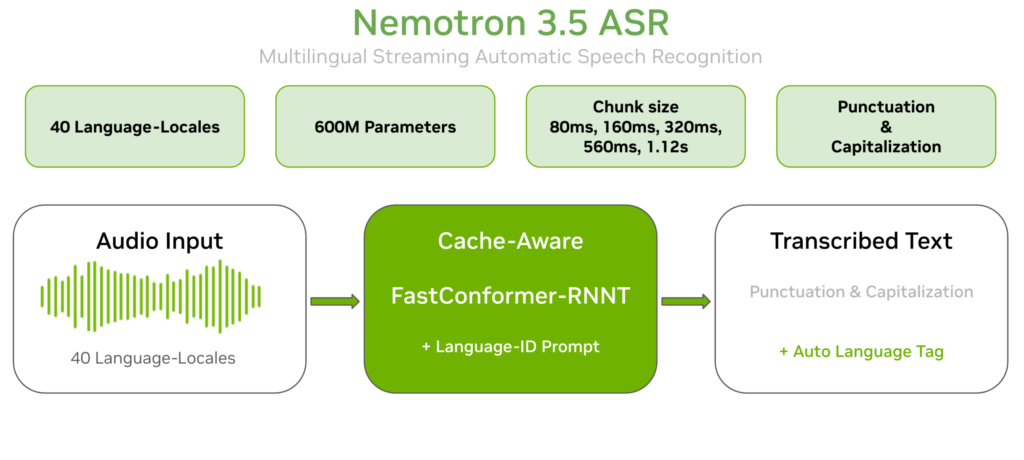
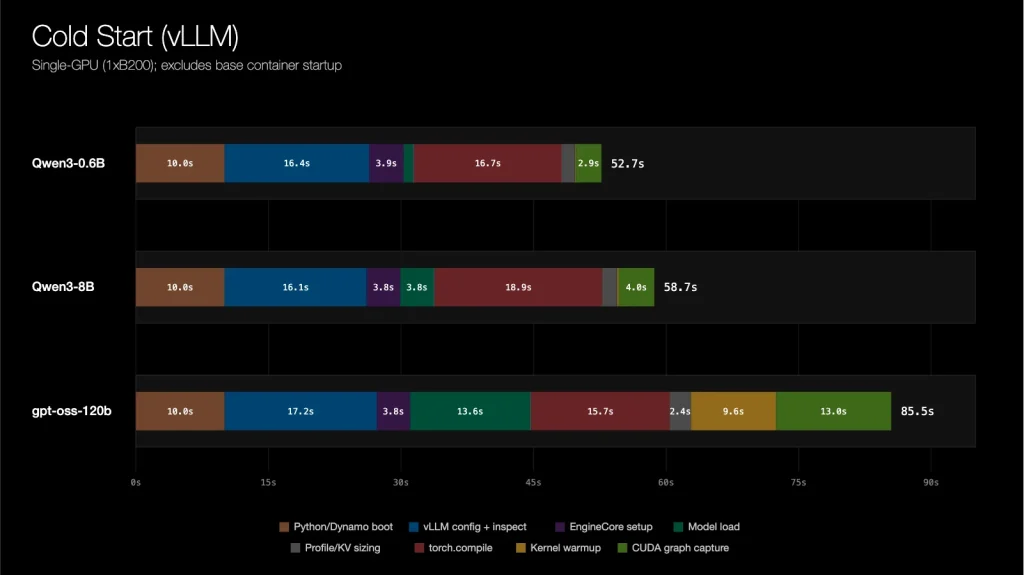
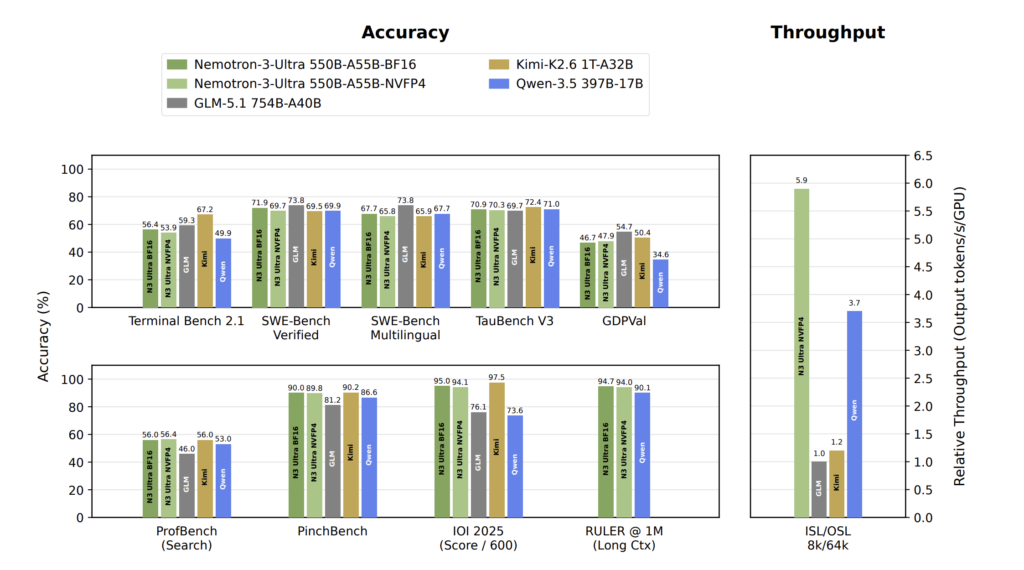
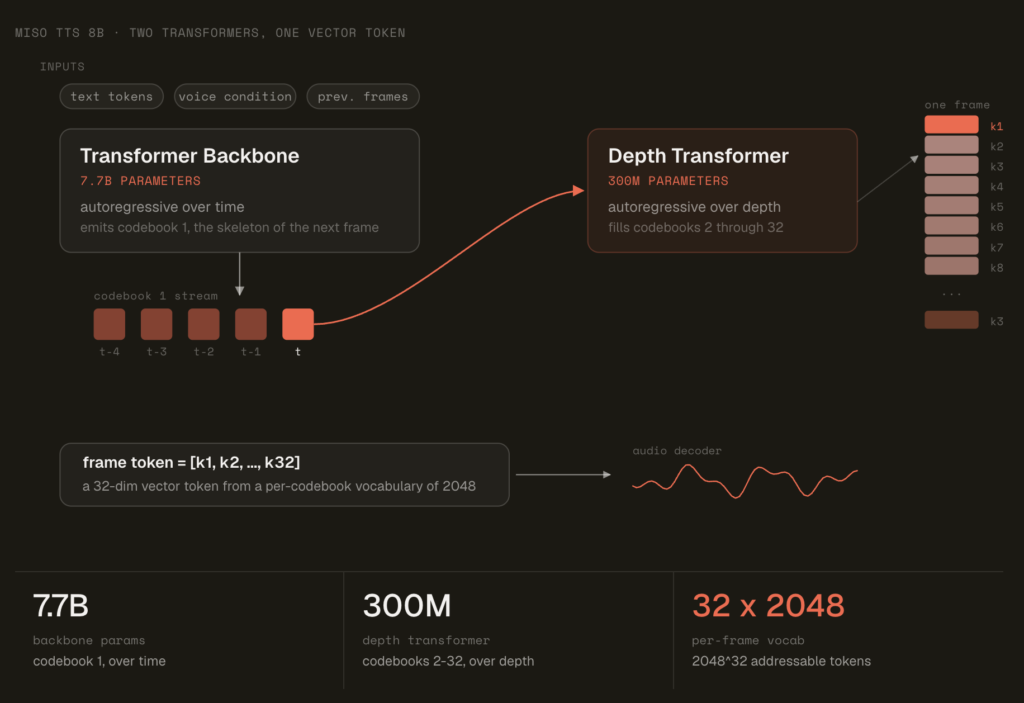
Google AI Releases DiffusionGemma, a 26B MoE Open Model Using Text Diffusion for Up to 4x Faster Generation
Google AI team including the Google DeepMind researchers have just released DiffusionGemma, an experimental open model for text generation. It uses text diffusion instead of standard autoregressive decoding. The model ships under a permissive Apache 2.0 license. Google positions it for devs and researchers exploring speed-critical, interactive local workflows. Examples include in-line editing, rapid iteration, […]