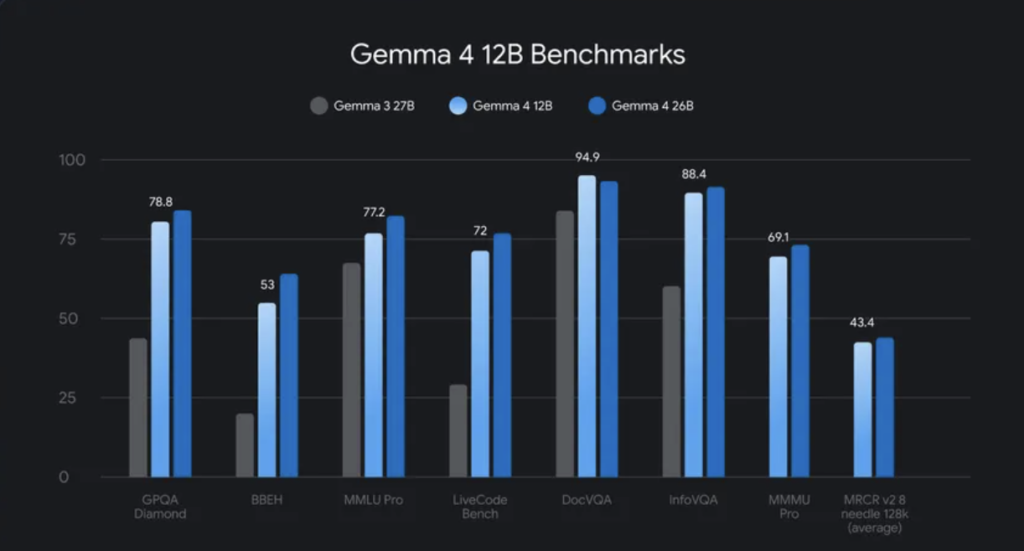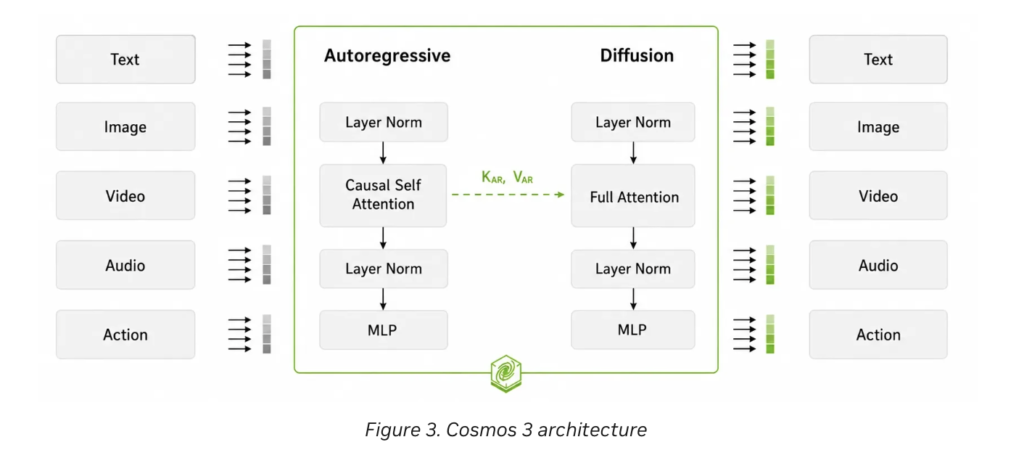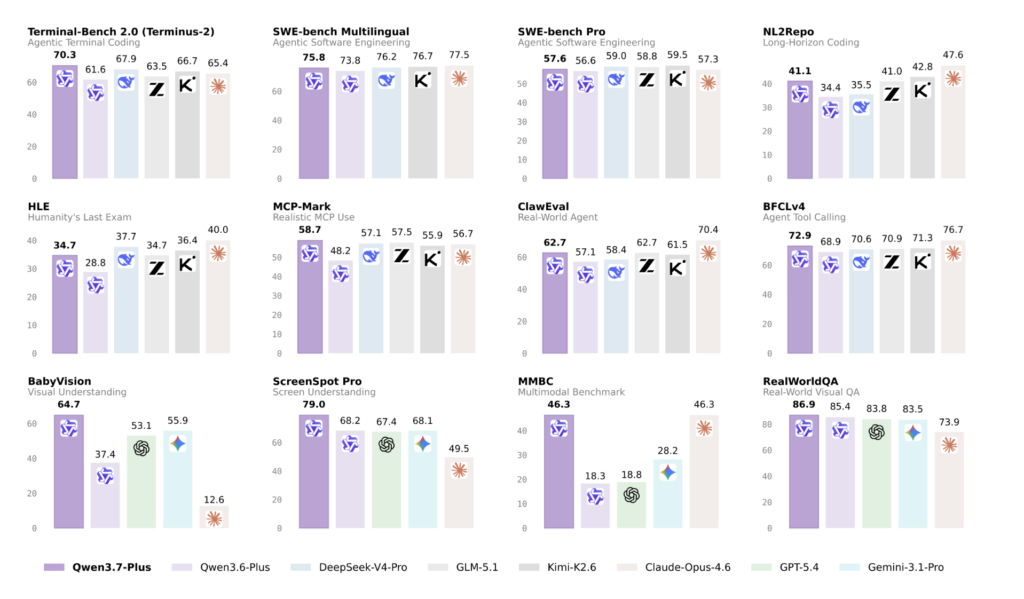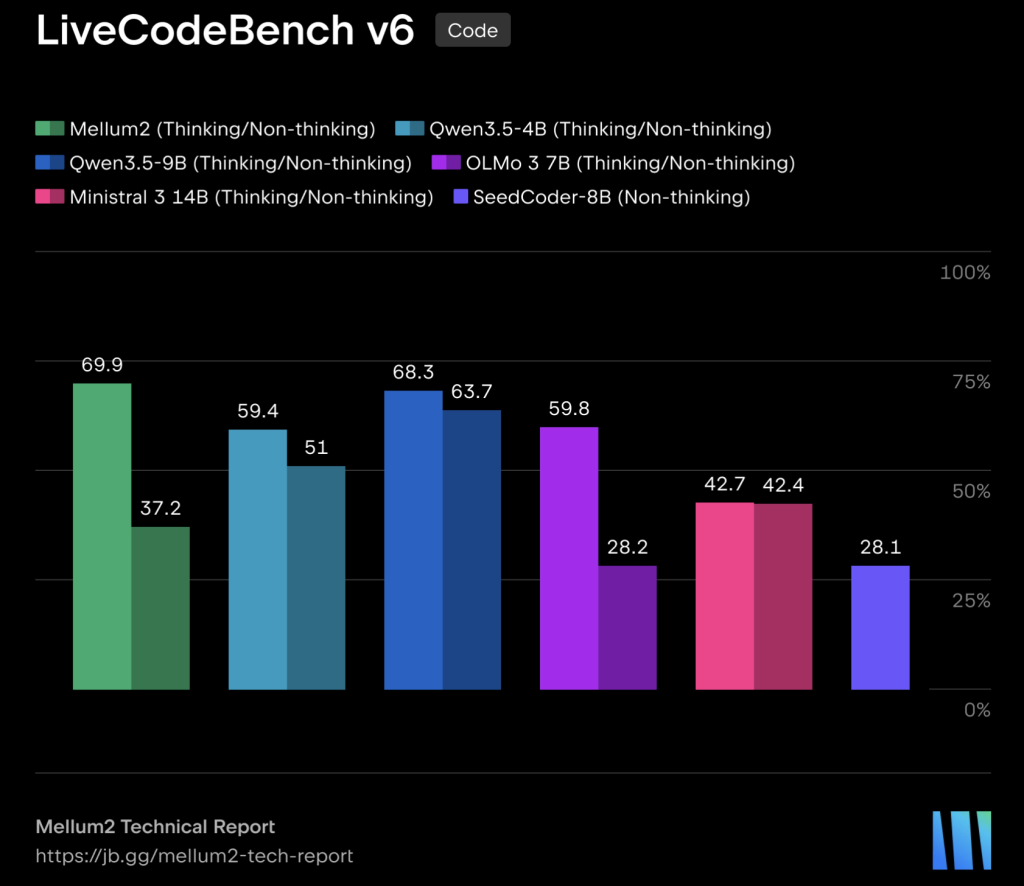
Meet OpenJarvis: A Local-First Framework for On-Device Personal AI Agents with Tools, Memory, and Learning
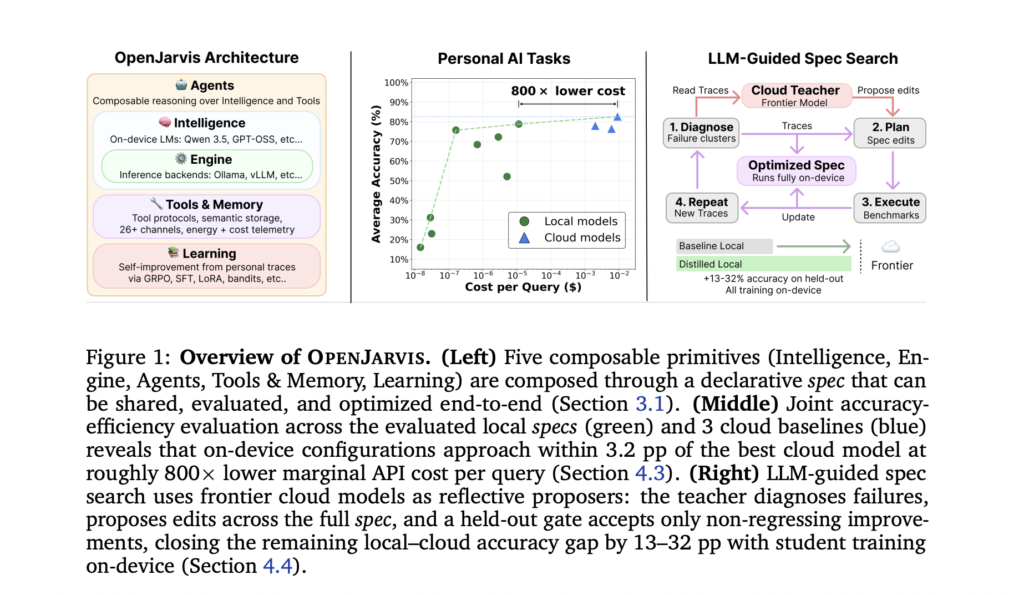
Researchers at Stanford University and Lambda Labs, have published the research paper for OpenJarvis, an open-source framework that runs inference, agents, memory, and learning entirely on-device. The open-weight models configured through OpenJarvis land within 3.2 percentage points of the best cloud model on average, at roughly 800× lower marginal API cost per query and roughly […]