
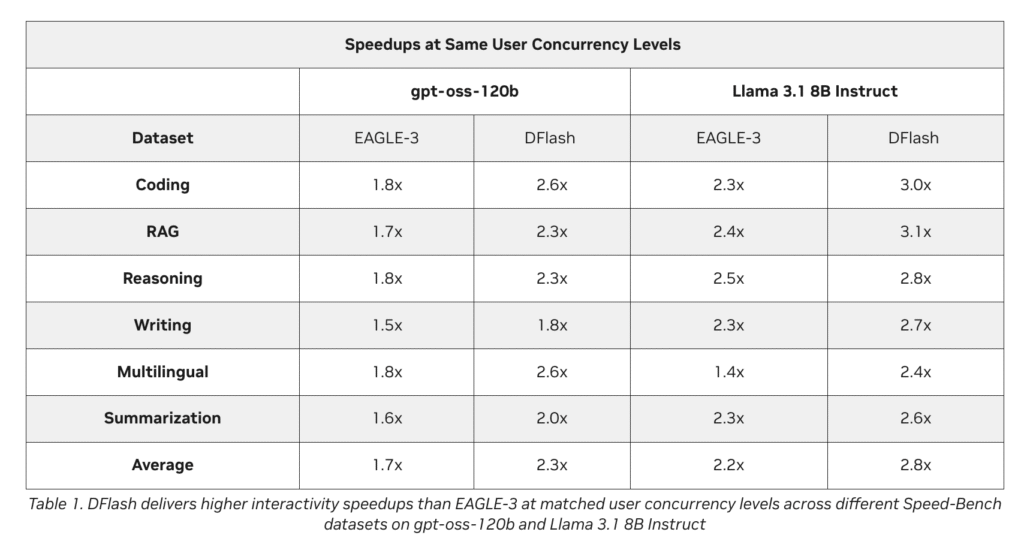
DFlash Speculative Decoding Drafts Whole Token Blocks in Parallel for Up to 15x Higher Throughput on NVIDIA Blackwell
Autoregressive large language models generate text one token at a time. Each token waits for the one before it. This serial loop leaves modern GPUs underused and keeps inference slow. The cost grows worse with long Chain-of-Thought reasoning models. Their lengthy outputs make latency the dominant part of generation. Speculative decoding is the standard fix. […]







