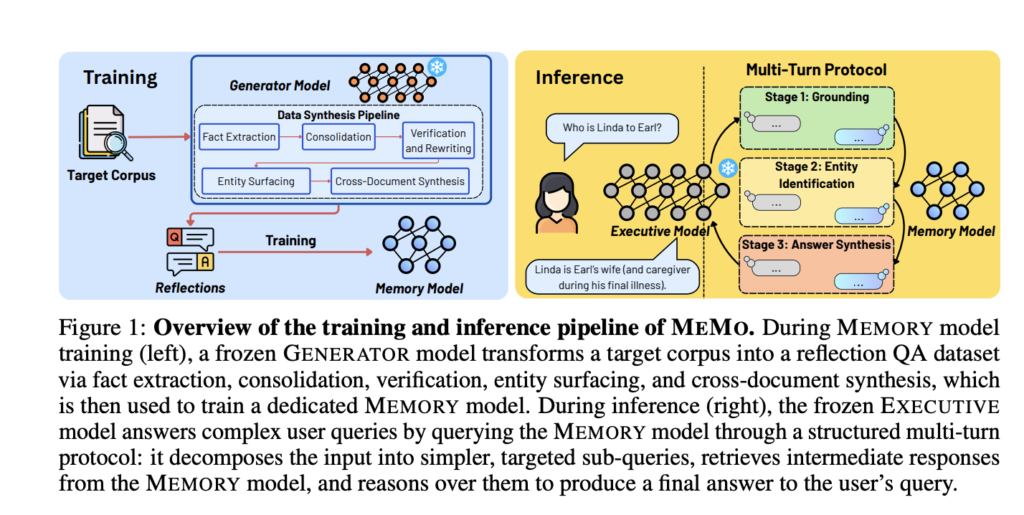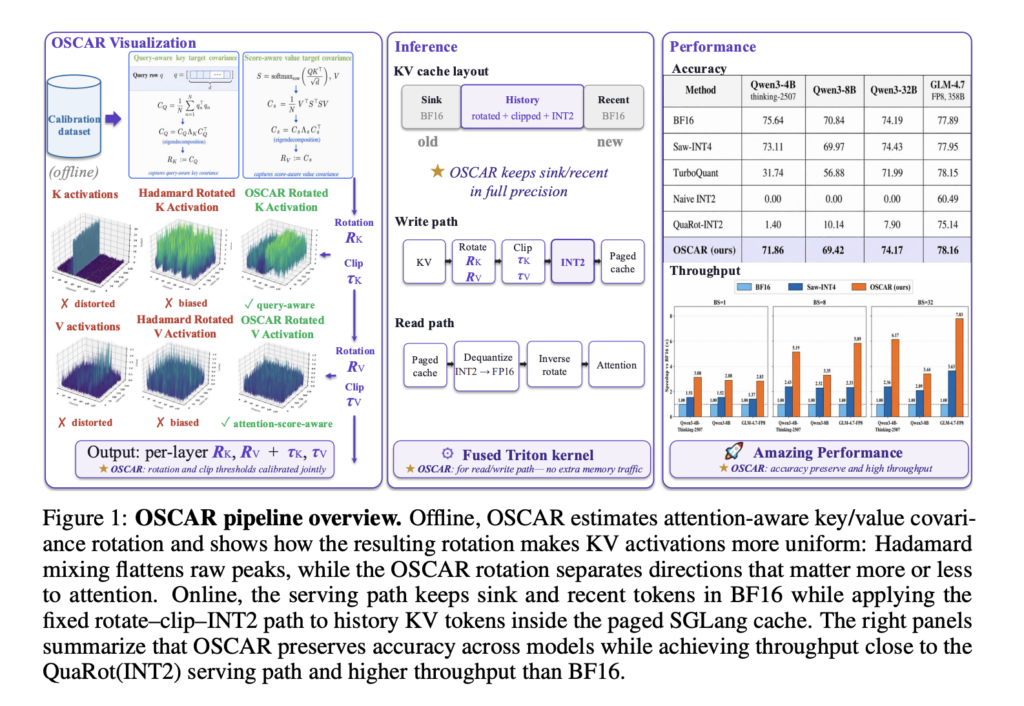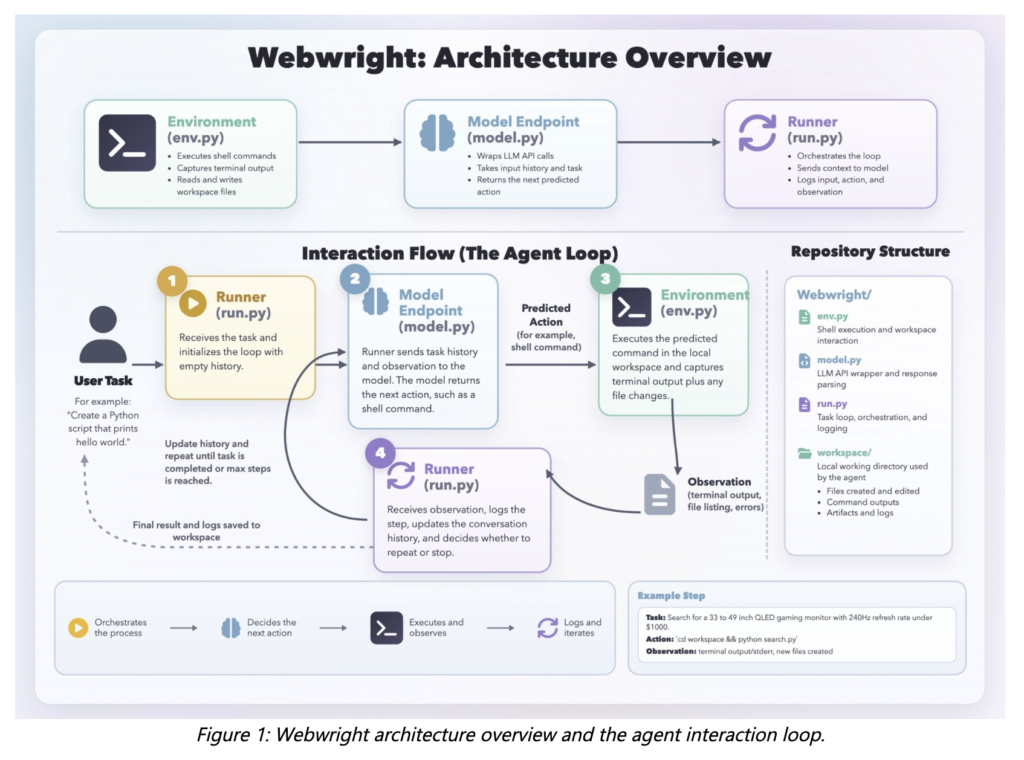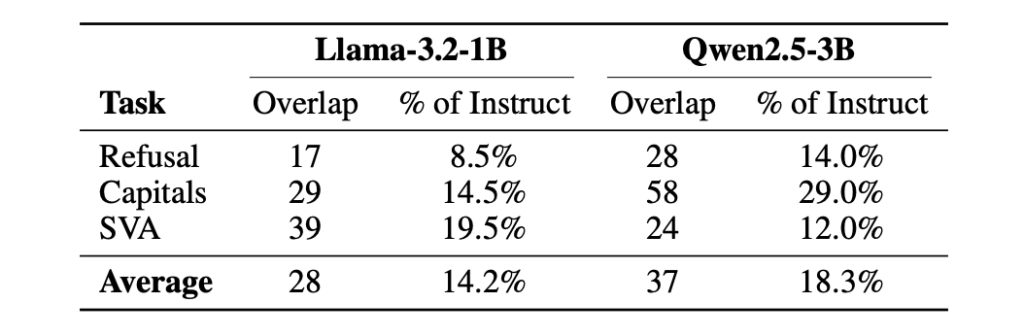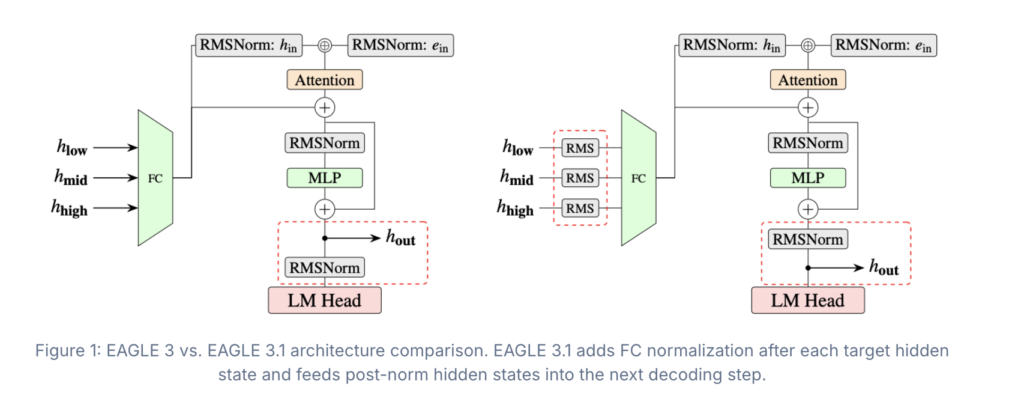
Meet EAGLE 3.1: The Speculative Decoding Algorithm That Fixes Attention Drift in LLM Inference
Speculative decoding is a technique for speeding up large language model inference. A small, fast draft model proposes several tokens. The large target model verifies them in parallel. If accepted, inference is faster. If rejected, the system falls back gracefully. EAGLE Team, vLLM Team, and TorchSpec Team has launched the EAGLE series including EAGLE 1, […]