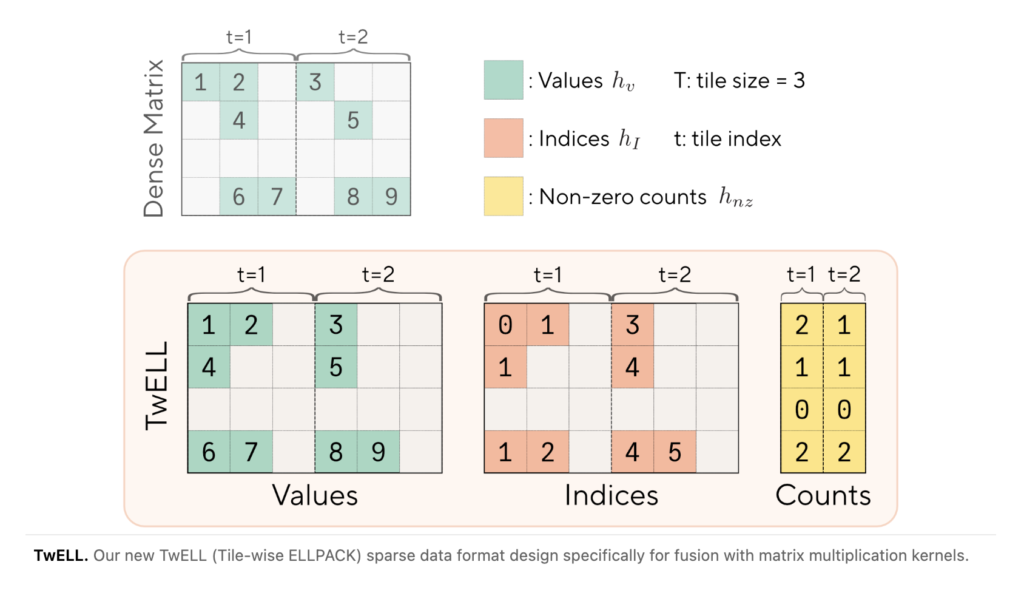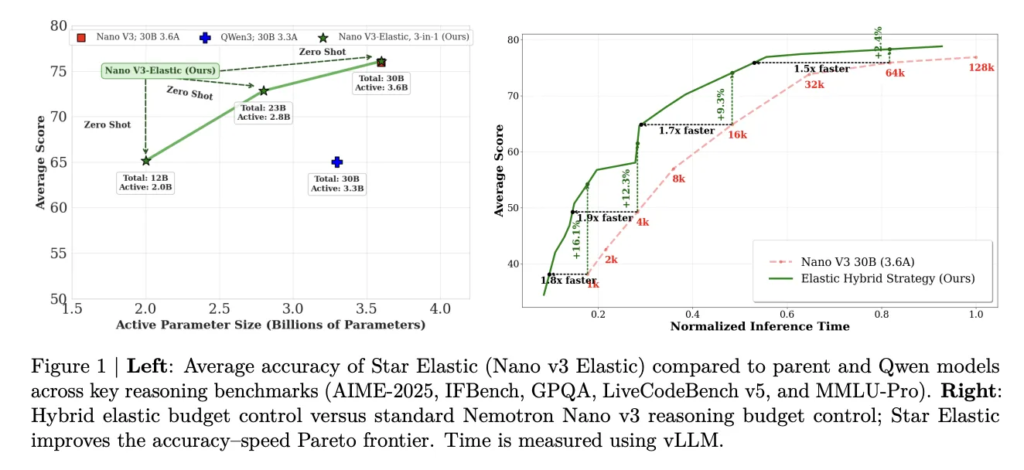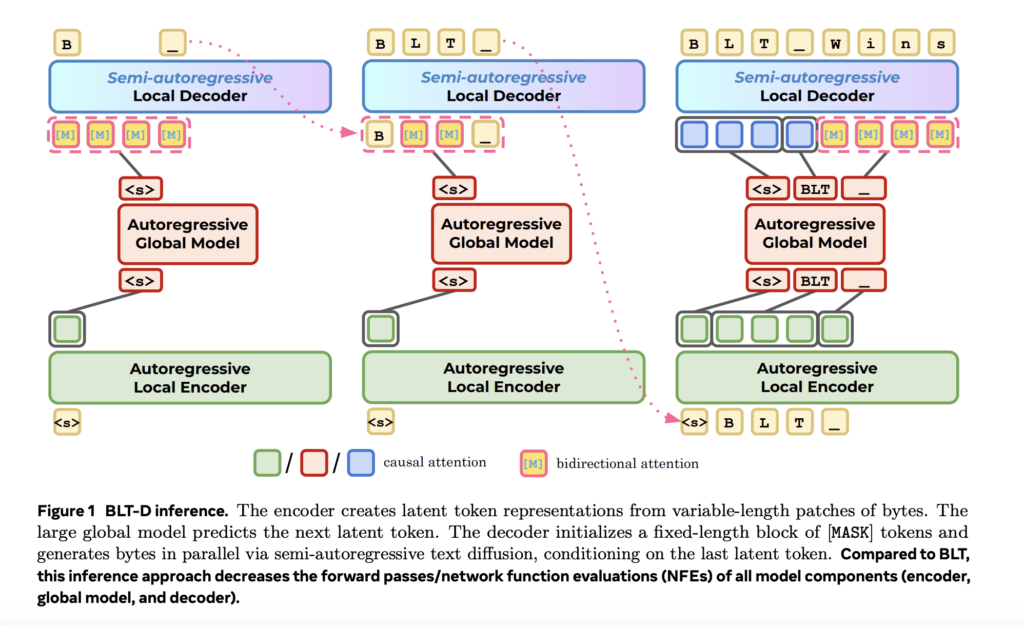
Meta and Stanford Researchers Propose Fast Byte Latent Transformer That Reduces Inference Memory Bandwidth by Over 50% Without Tokenization
A team of researchers from Meta, Stanford University, and the University of Washington have introduced three new methods that substantially accelerate generation in the Byte Latent Transformer (BLT) — a language model architecture that operates directly on raw bytes instead of tokens. Byte-Level Models Are Slow at Inference To understand what this new research solves, […]