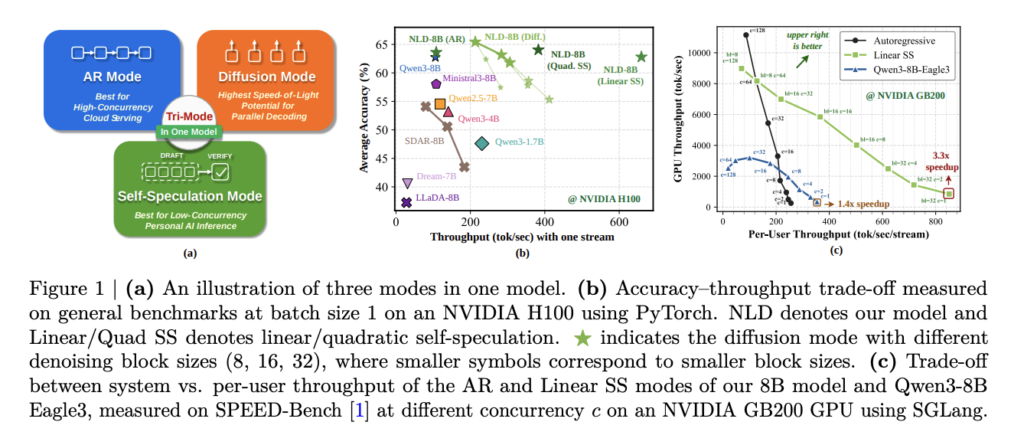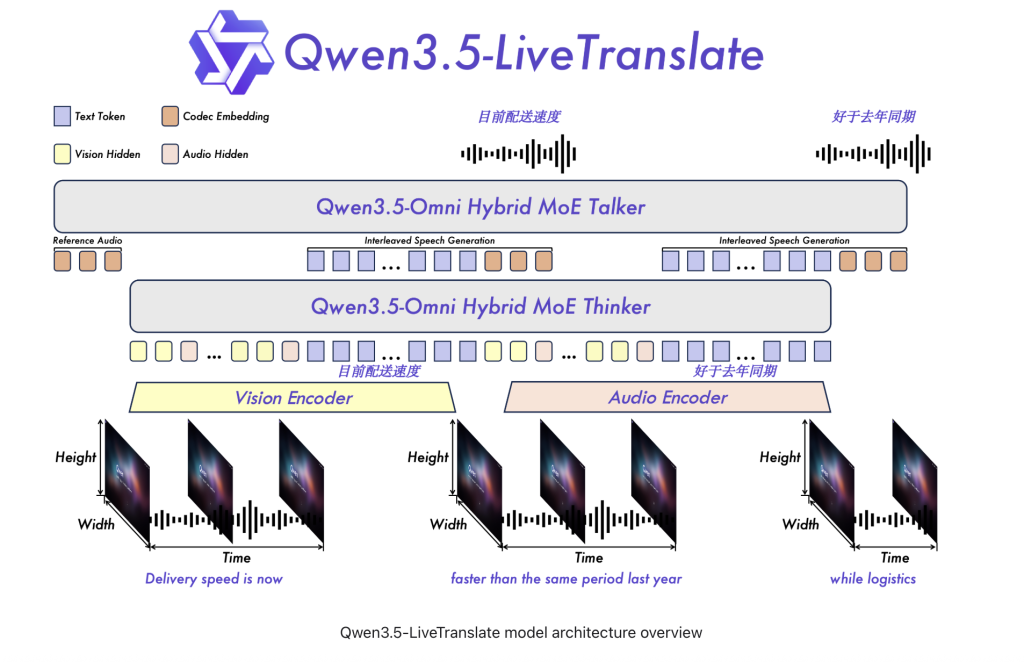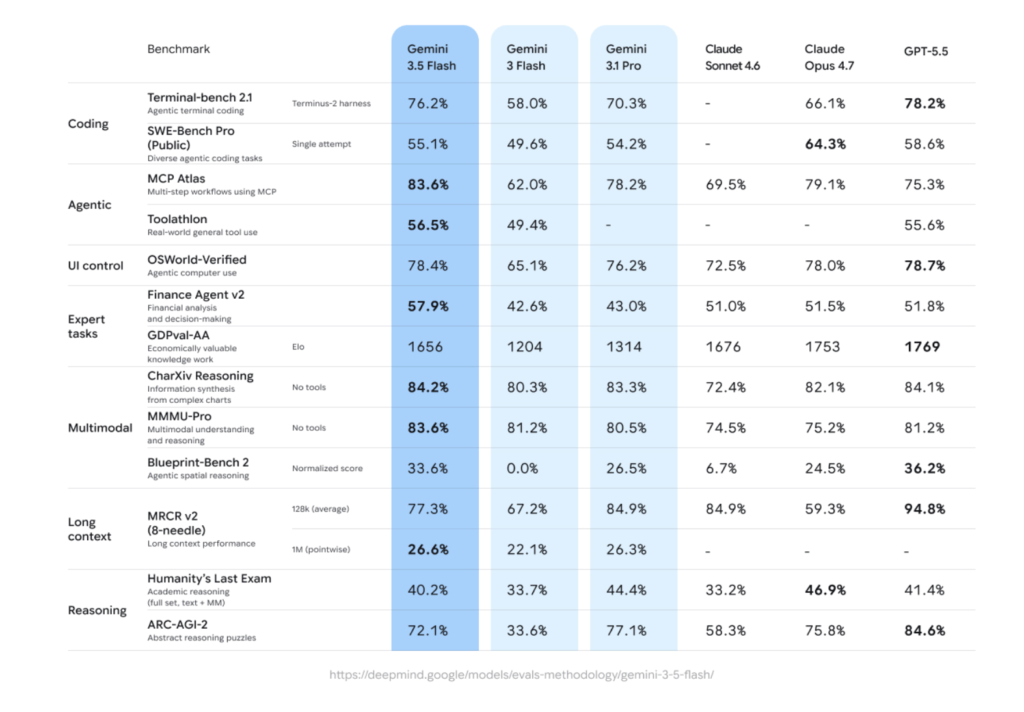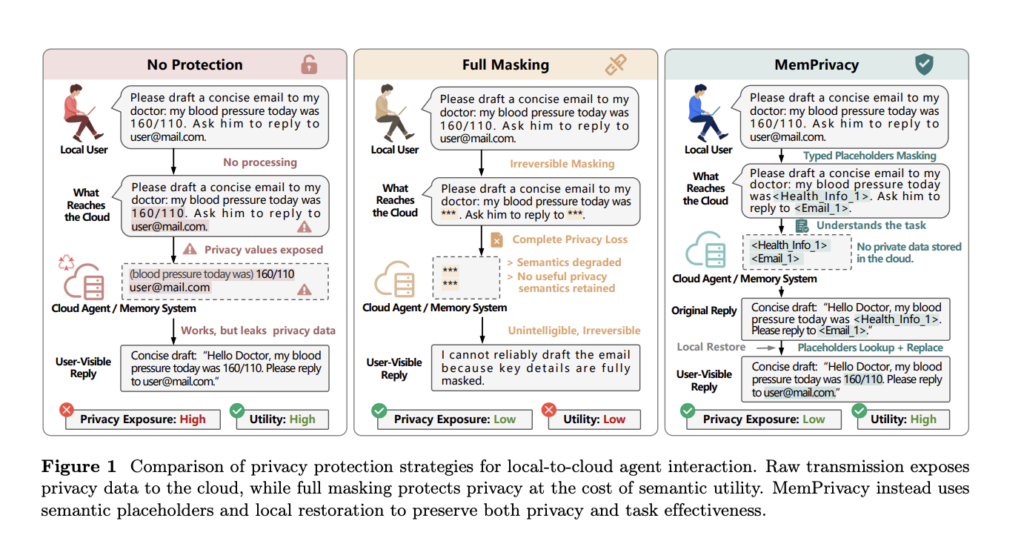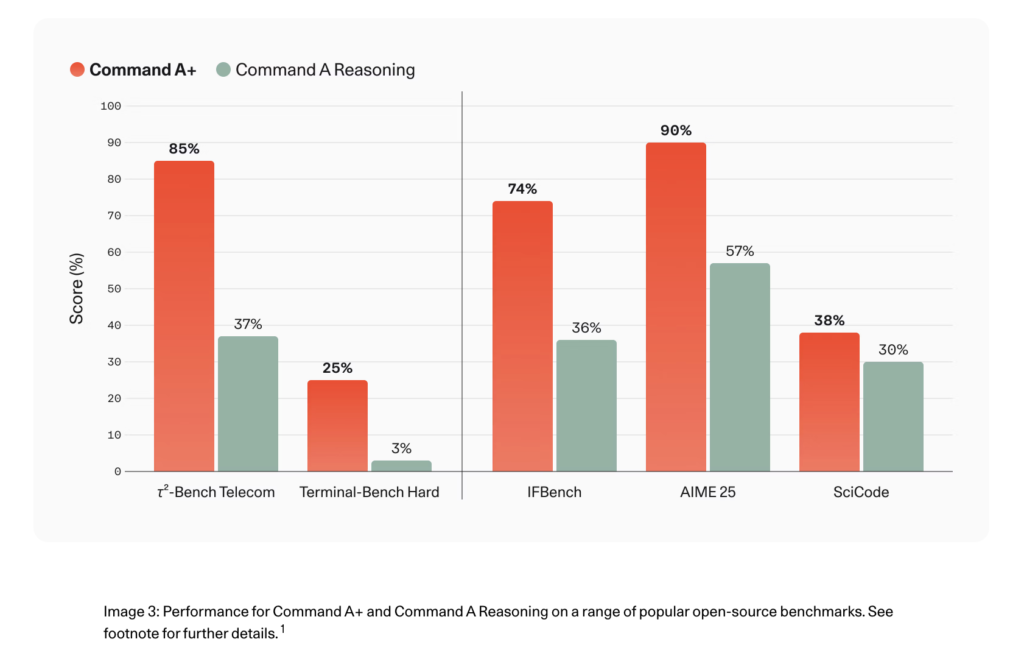
Cohere Releases Command A+: A 218B Sparse MoE Model for Agentic Workflows That Runs on as Few as Two H100 GPUs
Cohere just released Command A+, as an open-source model targeting enterprise agentic workflows. Available under an Apache 2.0 license, Command A+ is a mixture-of-experts (MoE) model built for high-performance agentic tasks with minimal compute overhead. The model is optimized for reasoning, agentic workflows, RAG, multilingual, and multimodal document processing. It unifies capabilities from four prior […]