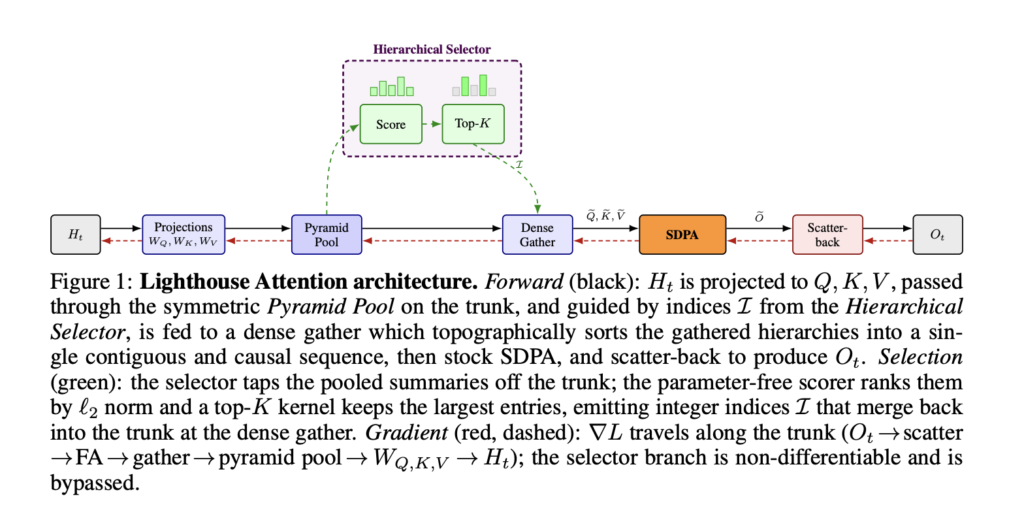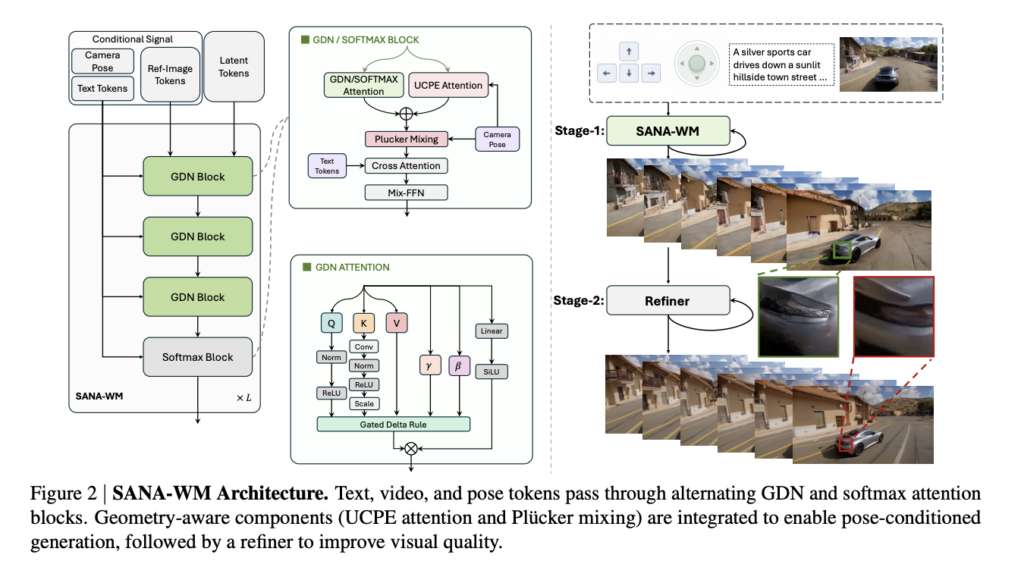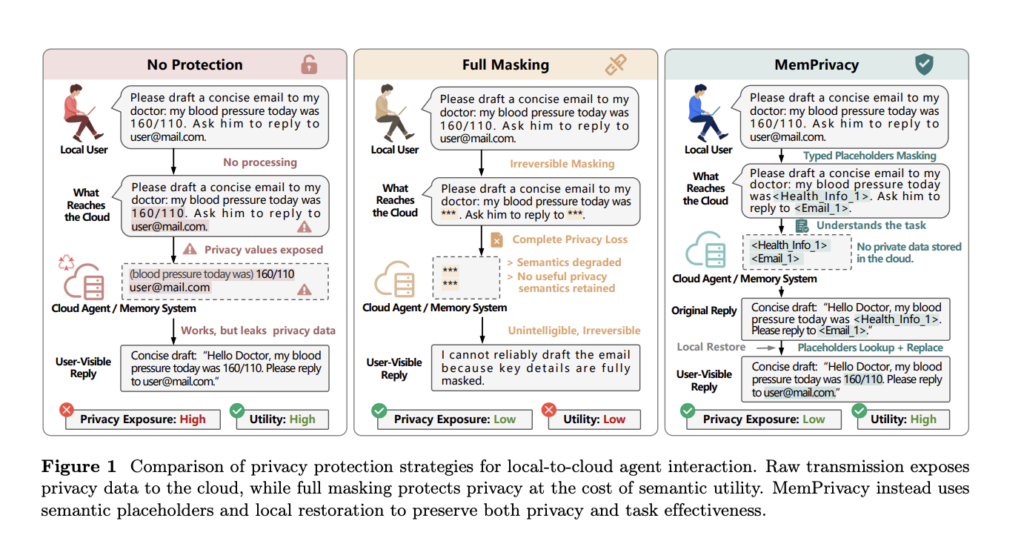
Meet MemPrivacy: An Edge-Cloud Framework that Uses Local Reversible Pseudonymization to Protect User Data Without Breaking Memory Utility
As LLM-powered agents move from research to production, one design tension is becoming harder to ignore: the more useful cloud-hosted memory becomes, the more private user data it exposes. Researchers from MemTensor (Shanghai), HONOR Device and Tongji University have introduced MemPrivacy, a framework that attempts to resolve this tension without sacrificing the utility that makes […]