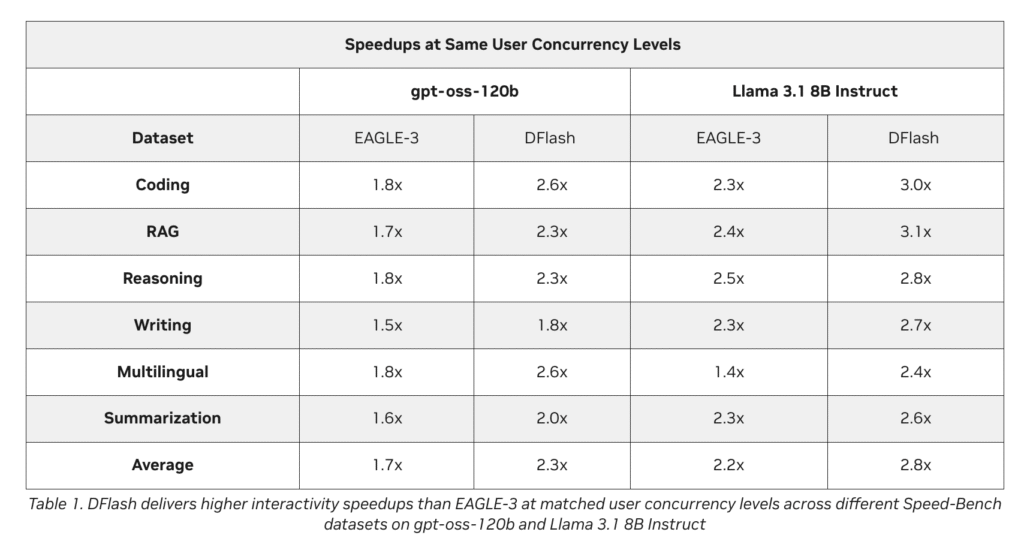
NVIDIA HORIZON: A Hands-Free Agent that Evolves Git Worktrees and Hits 100% RTL Benchmark Completion
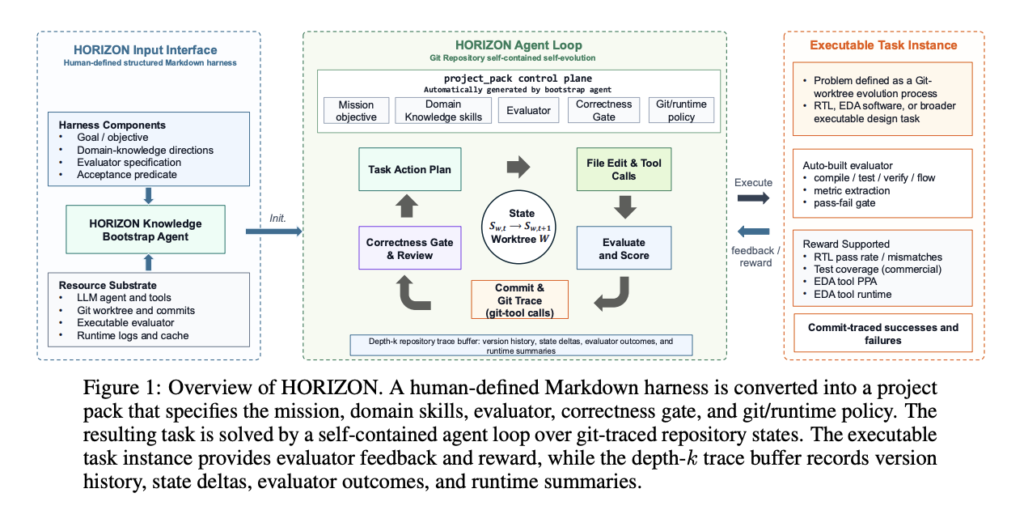
NVIDIA Research introduced HORIZON, a hands-free agent framework for hardware design. It treats hardware design as repository-level code evolution. This research team exercises the register-transfer level (RTL) instantiation. A structured Markdown harness becomes a project pack. A self-contained agent loop then evolves an isolated git worktree. It commits a version only when an executable acceptance […]