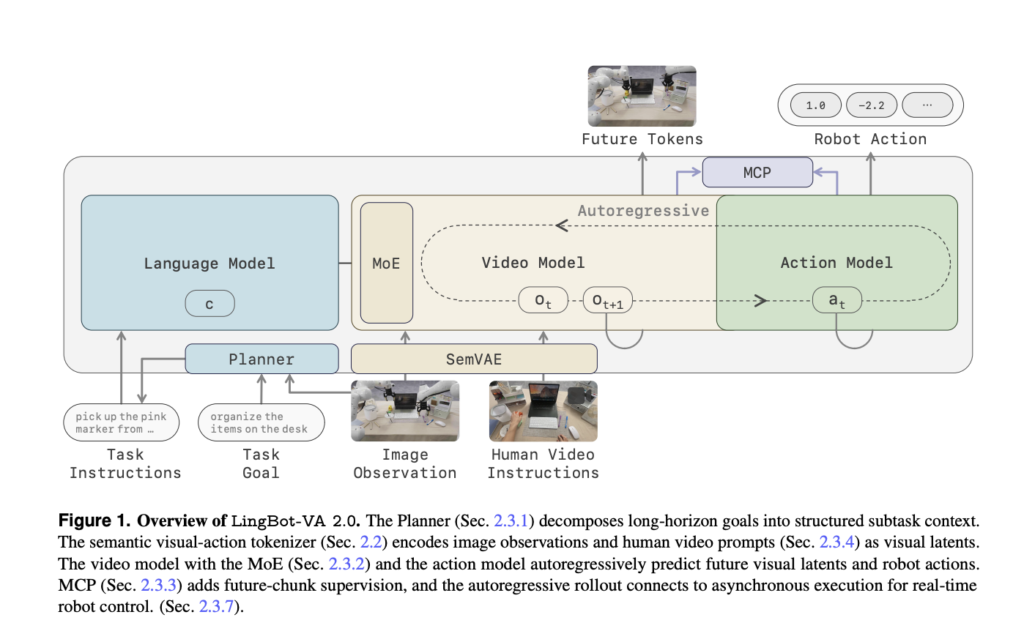
A Coding Guide to NVIDIA’s Tile-Based GPU Programming: From cuTile and Triton Kernels to Flash Attention
In this tutorial, we explore TileGym GPU programming by building a practical Colab workflow that runs across different hardware conditions. We begin by probing the available CUDA environment, checking whether NVIDIA cuTile runs directly, and falling back to Triton when standard Colab GPUs lack the required cuTile stack. Through this setup, we learn the core […]