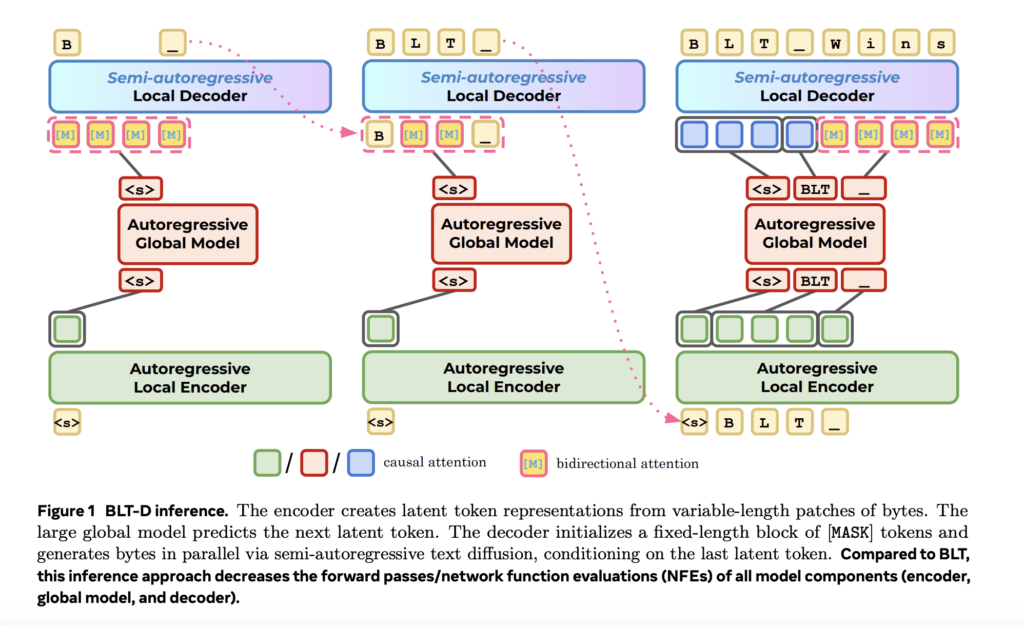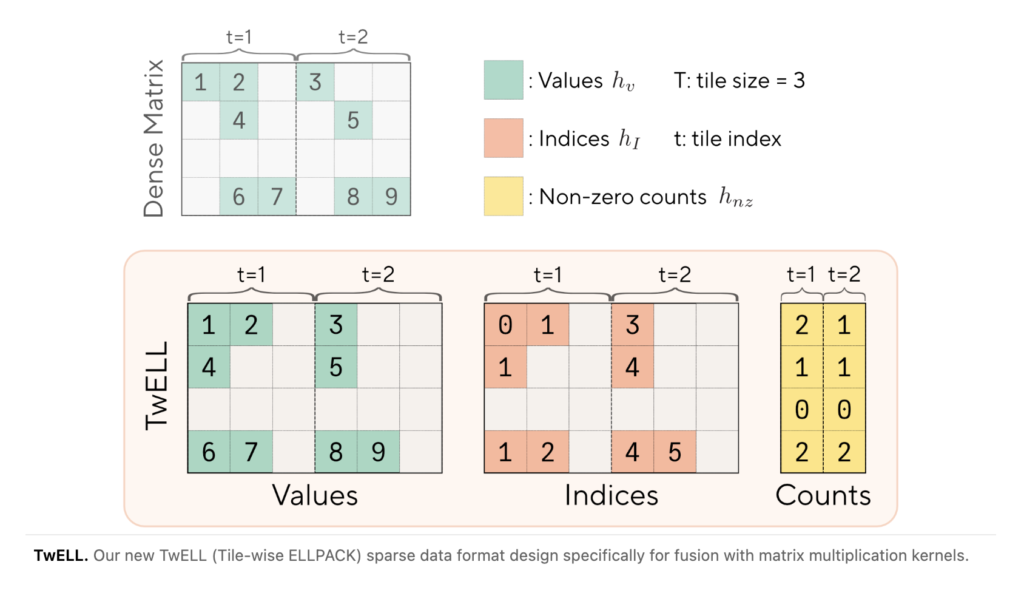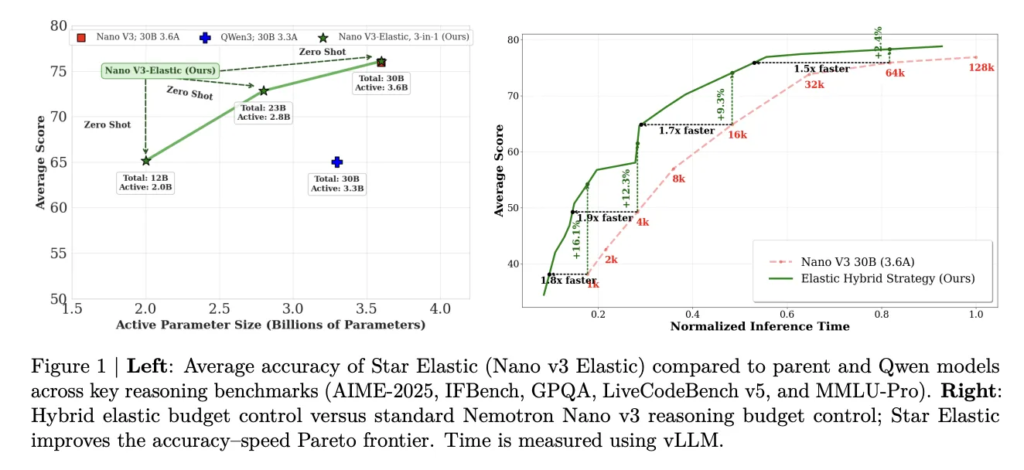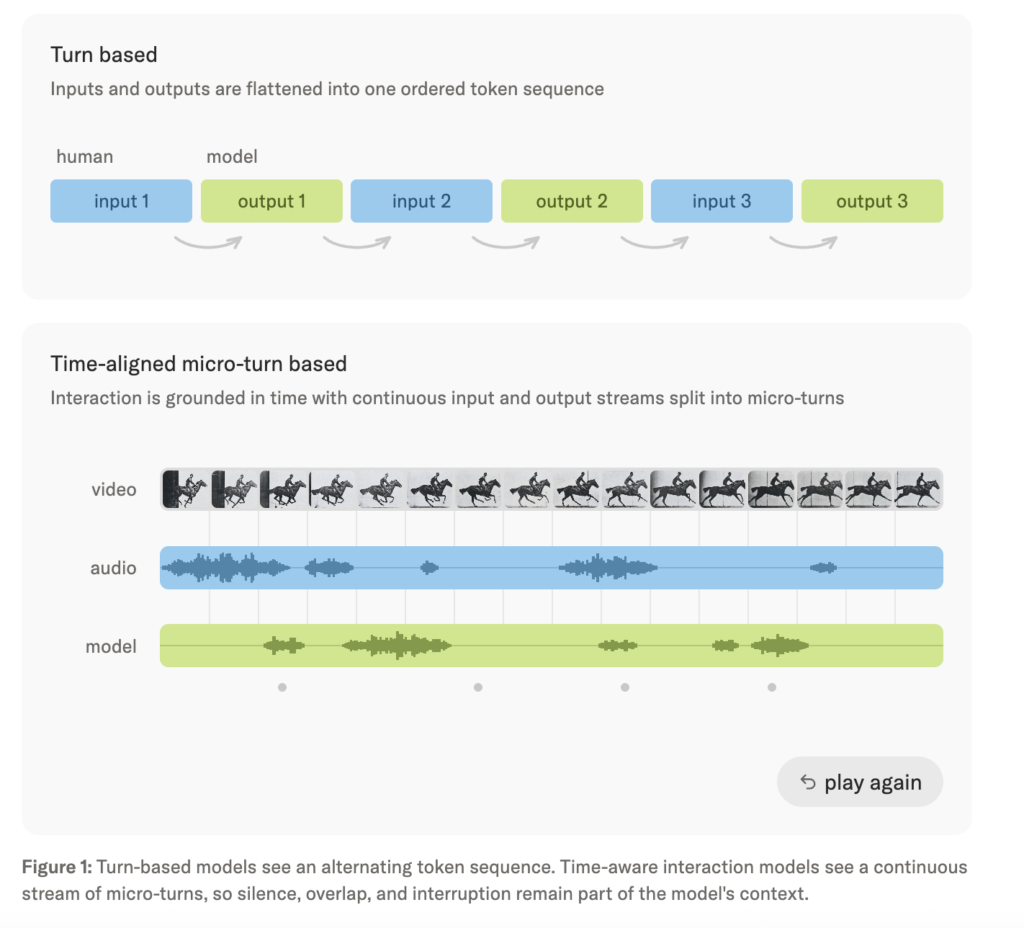
Mira Murati’s Thinking Machines Lab Introduces Interaction Models: A Native Multimodal Architecture for Real-Time Human-AI Collaboration
Most AI systems today work in turns. You type or speak, the model waits, processes your input, and then responds. That’s the entire interaction loop. Thinking Machines Lab, an AI research lab, is arguing that this model of interaction is a fundamental bottleneck. Thinking Machines Lab team introduced a research preview of a new class […]