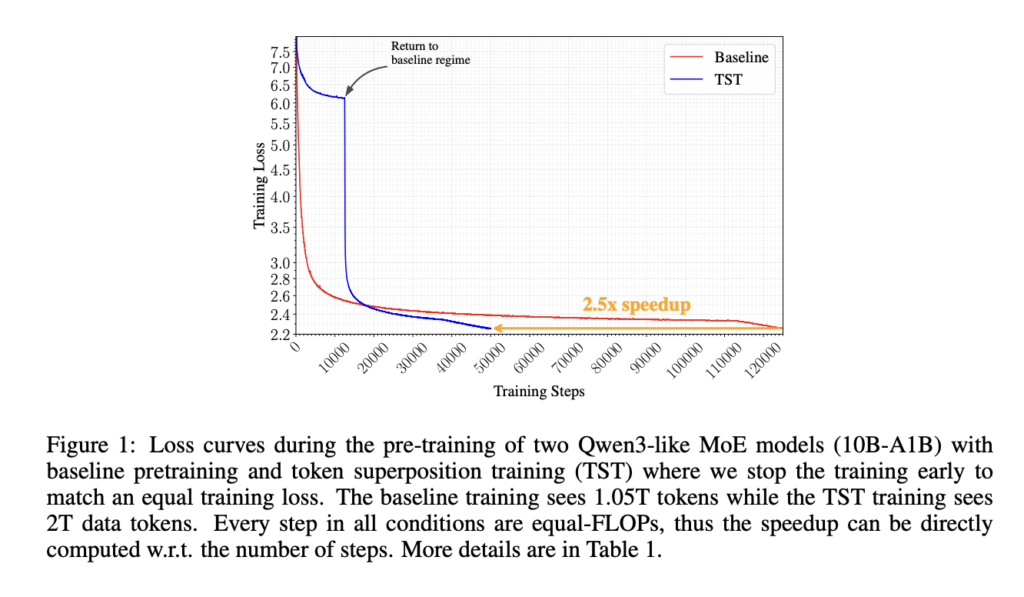
Nous Research Releases Token Superposition Training to Speed Up LLM Pre-Training by Up to 2.5x Across 270M to 10B Parameter Models
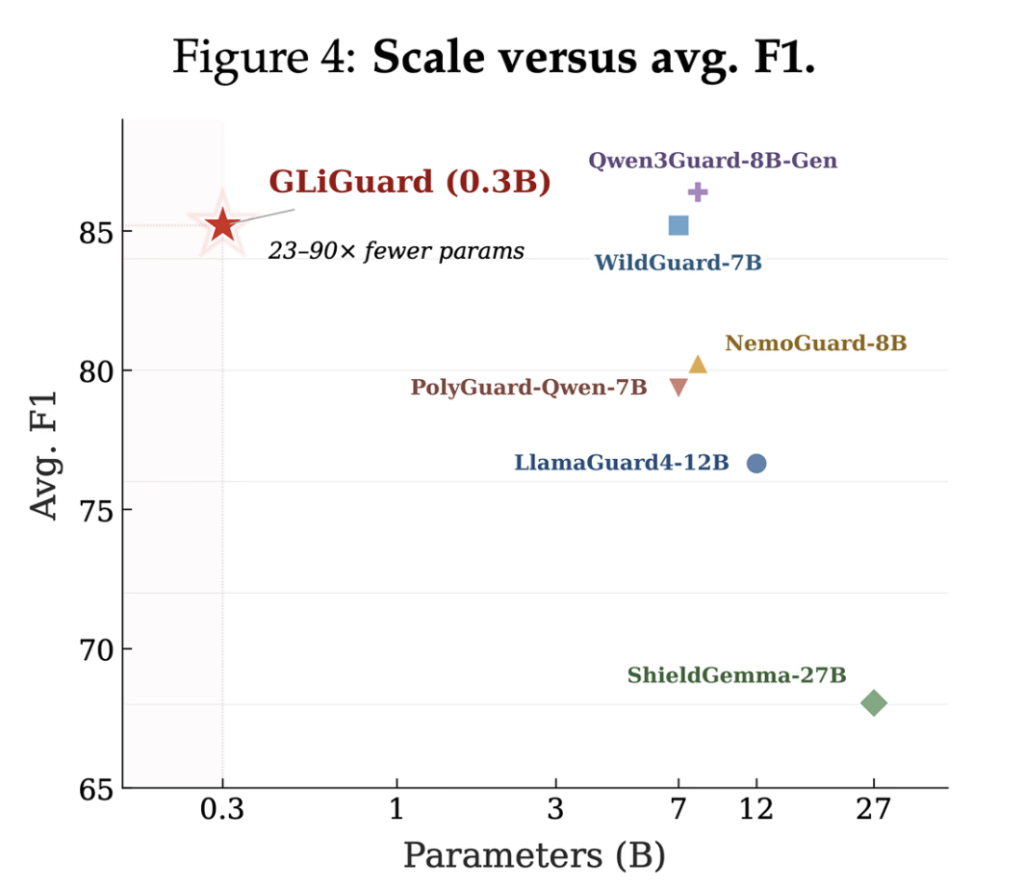
Pre-training large language models is expensive enough that even modest efficiency improvements can translate into meaningful cost and time savings. Nous Research is releasing Token Superposition Training (TST), a method that substantially reduces pre-training wall-clock time at fixed compute without touching the model architecture, optimizer, tokenizer, parallelism strategy, or training data. At the 10B-A1B mixture-of-experts […]