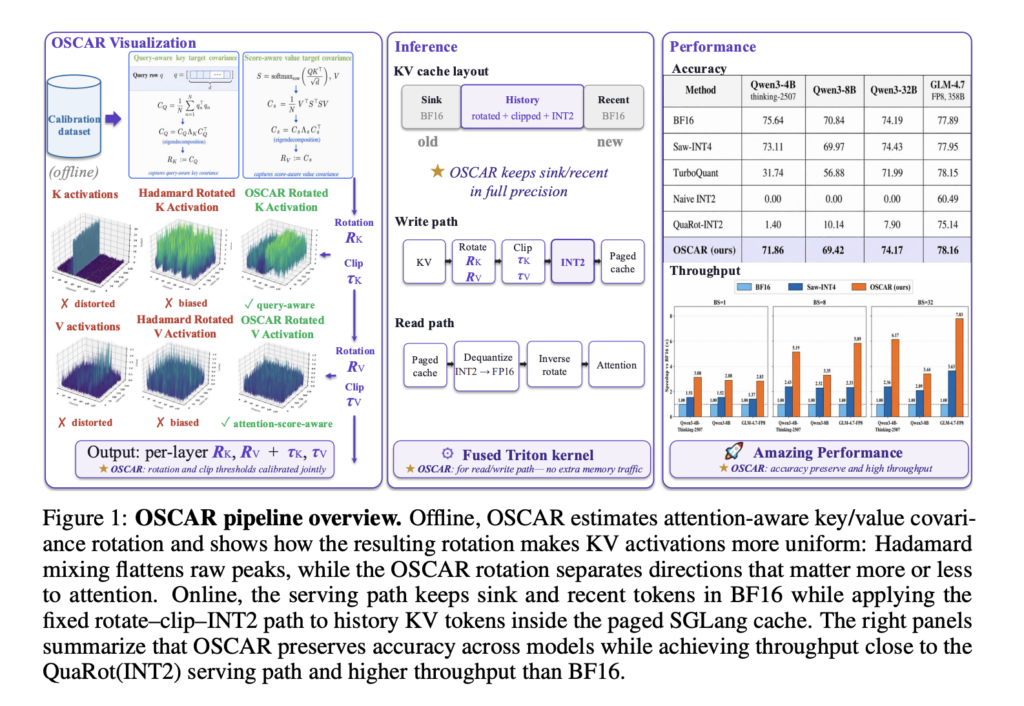
Together AI Open-Sources OSCAR: An Attention-Aware 2-Bit KV Cache Quantization System for Long-Context LLM Serving
Long-context inference makes the KV cache one of the main costs of serving LLMs. During autoregressive decoding, the cache grows with context length, batch size, and model depth. At high batch sizes and long contexts with 100K tokens across dozens of concurrent requests the KV cache consumes a large fraction of GPU memory. Compressing it […]