

The Hidden Cost of Operating Without Visual Intelligence in Logistics and Supply Chain Operations
How visual intelligence in logistics and supply chain improves visibility, prevents losses, and strengthens operational efficiency.
Category Added in a WPeMatico Campaign
How visual intelligence in logistics and supply chain improves visibility, prevents losses, and strengthens operational efficiency.

How AI visual intelligence in logistics and supply chain improves visibility, prevents losses, and strengthens operational efficiency.

Watch: Rain fury triggers flash floods in Arunachal, 15 homes swept away
Watch: Rain fury triggers flash floods in Arunachal, 15 homes swept away Read More »

This Indian startup is betting its own money on orbit, twice over. Deets inside
This Indian startup is betting its own money on orbit, twice over. Deets inside Read More »

Indian investors lead the world in AI adoption for finance, but still trust humans with the final call The Economic Times

UN sounds El Nino alarm: Weak monsoon, food inflation, water stress for India
UN sounds El Nino alarm: Weak monsoon, food inflation, water stress for India Read More »
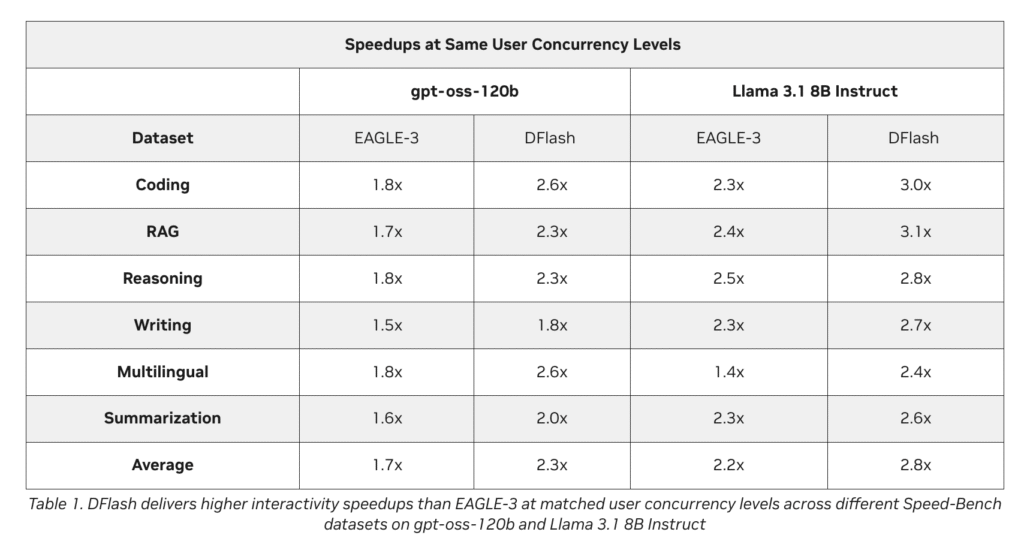
Autoregressive large language models generate text one token at a time. Each token waits for the one before it. This serial loop leaves modern GPUs underused and keeps inference slow. The cost grows worse with long Chain-of-Thought reasoning models. Their lengthy outputs make latency the dominant part of generation. Speculative decoding is the standard fix.

El Nino to shrink sardine and mackerel fish in Indian Ocean, warning issued
El Nino to shrink sardine and mackerel fish in Indian Ocean, warning issued Read More »

Former OpenAI Team Member Moves To India, Calls It A ‘Global Opportunity Hub’ NDTV
Former OpenAI Team Member Moves To India, Calls It A ‘Global Opportunity Hub’ – NDTV Read More »

Anthropic launches Claude Tag: Everything you need to know about the Slack-native AI agent The Economic Times