

Syke Founder Alistair Maiden Joins Flank
Alistair Maiden, who created the well-known legal engineering group Syke before selling it to Consilio, has joined legal agent maker Flank in a senior role. …
Alistair Maiden, who created the well-known legal engineering group Syke before selling it to Consilio, has joined legal agent maker Flank in a senior role. …

This place in India is defying the monsoon crisis with 96% excess rain
This place in India is defying the monsoon crisis with 96% excess rain Read More »
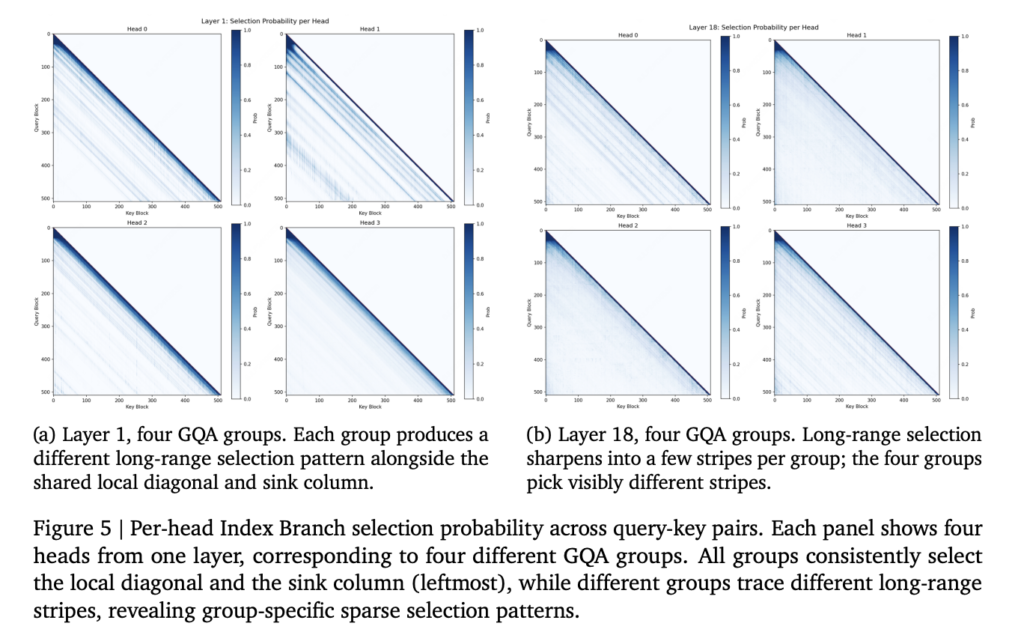
MiniMax released MSA (MiniMax Sparse Attention), a sparse attention method built directly on Grouped Query Attention (GQA). It targets one bottleneck: the quadratic cost of softmax attention at long context. The MiniMax research team tested it inside a 109B-parameter Mixture-of-Experts model trained with native multimodal data. They also open-sourced an inference kernel and shipped a

The Latest: G7 summit focuses on contentious future of AI and US dominance of the industry

China securities regulator warns against speculating on ‘tech hype’ and using AI for stock picking CNBC

Why this year’s monsoon delay is giving Mumbai nightmares
Why this year’s monsoon delay is giving Mumbai nightmares Read More »

‘A signal of where power sits’: Trump and world leaders joined by OpenAI, Anthropic, Google at G7 CNBC

While this is the first time Telegram has faced such a restriction in India, the platform launched by Russia-born Pavel Durov in August 2013 has come under bans or other punitive actions in several countries in the past.

