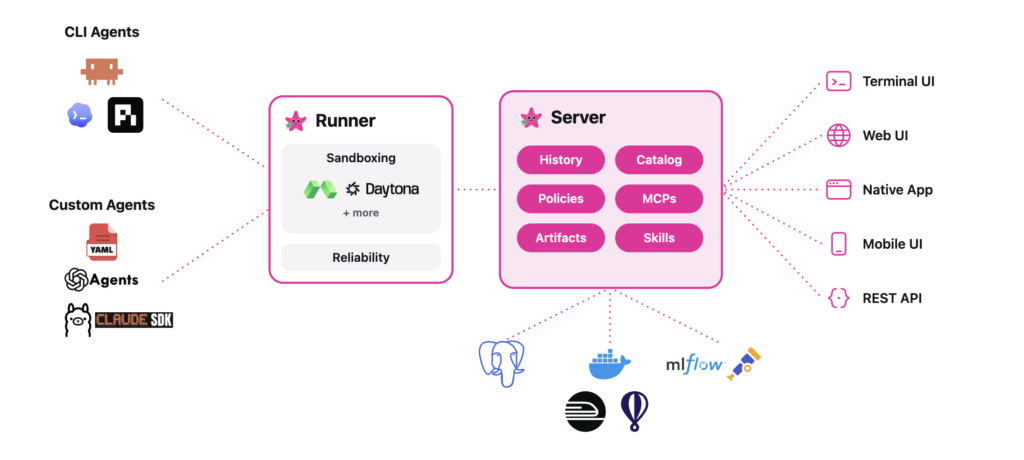
Meet Flash-KMeans: An IO-Aware, Exact K-Means That Runs Over 200× Faster Than FAISS on GPUs
k-means has been an offline tool for decades. You run it once to preprocess data, then move on. A team of researchers from UC Berkeley and UT Austin released Flash-KMeans, a new open-source library that targets a different setting. Modern AI pipelines now call k-means inside training and inference loops. At that frequency, latency per […]