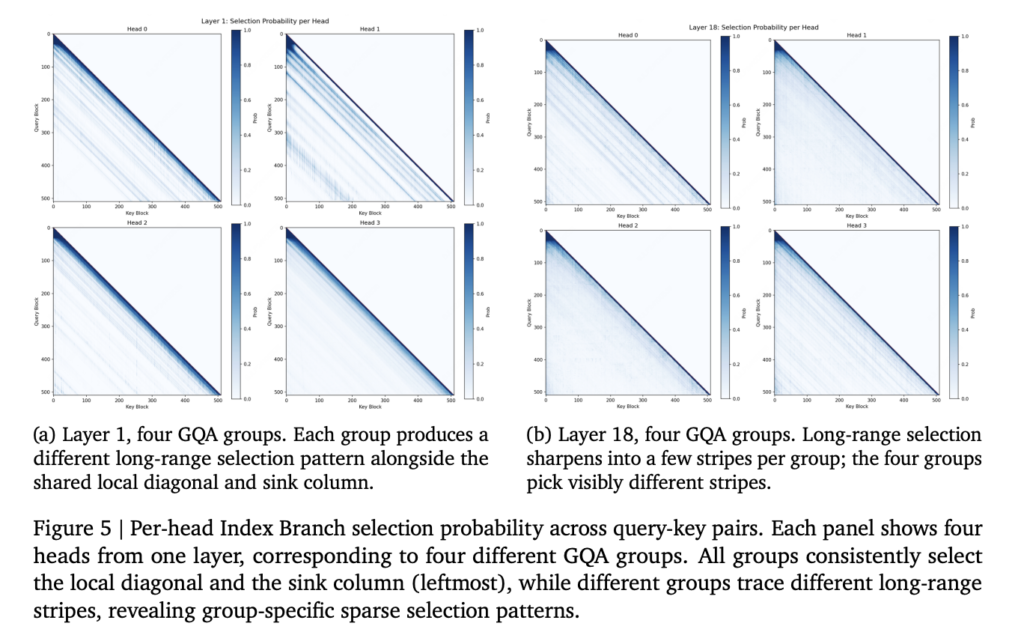
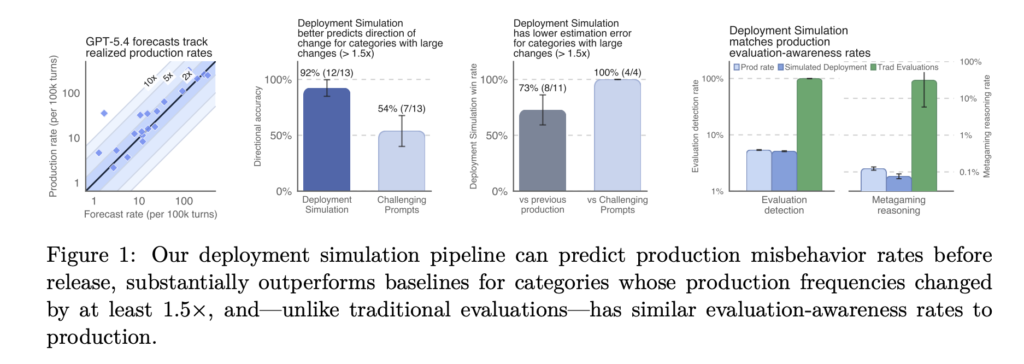
Vercel Releases Eve: An Open-Source AI Agent Framework Where Each Agent is a Directory of Files Mapped to Capabilities
Vercel has released eve, an open-source framework for building, running, and scaling agents. The project is published as the npm package eve, licensed under Apache-2.0. Building an agent should mean defining what it does. It should not mean assembling all the plumbing that an agent needs to run in production. eve is the framework Vercel […]