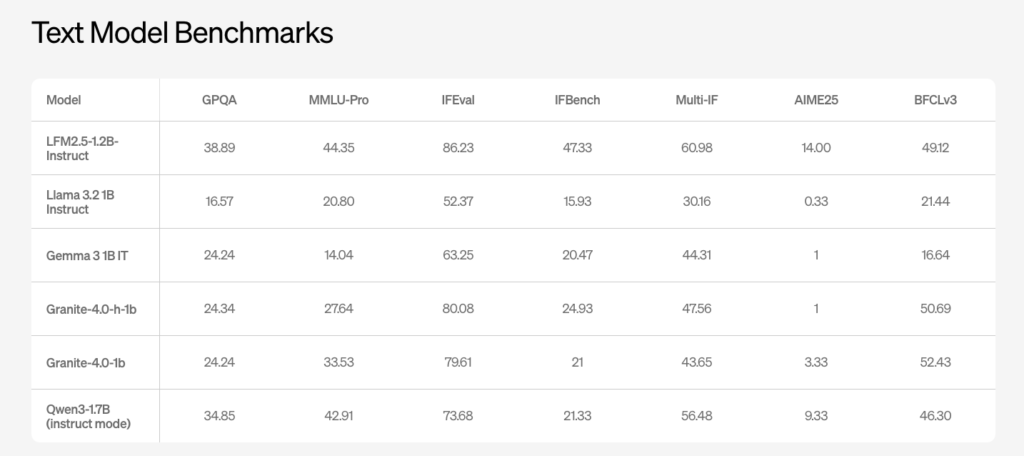
A Coding Implementation to Build a Unified Apache Beam Pipeline Demonstrating Batch and Stream Processing with Event-Time Windowing Using DirectRunner
In this tutorial, we demonstrate how to build a unified Apache Beam pipeline that works seamlessly in both batch and stream-like modes using the DirectRunner. We generate synthetic, event-time–aware data and apply fixed windowing with triggers and allowed lateness to demonstrate how Apache Beam consistently handles both on-time and late events. By switching only the […]