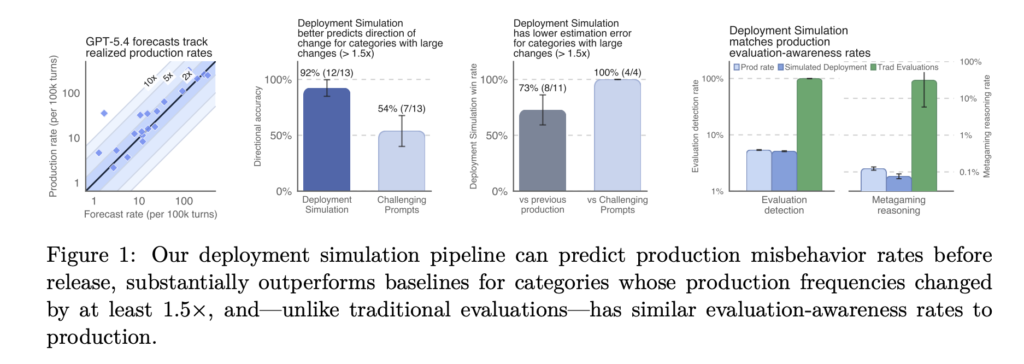
OpenAI’s Deployment Simulation Extends Pre-Deployment Risk Assessment to Agentic Coding Through Simulated Tool Calls
OpenAI published a new pre-deployment safety method called Deployment Simulation. The idea is direct. Before a model ships, simulate its deployment first. Replay past conversations through the new candidate model. Then study how it behaves in realistic contexts. OpenAI already uses insights from the method during model development. It has informed mitigations and deployment decisions, […]