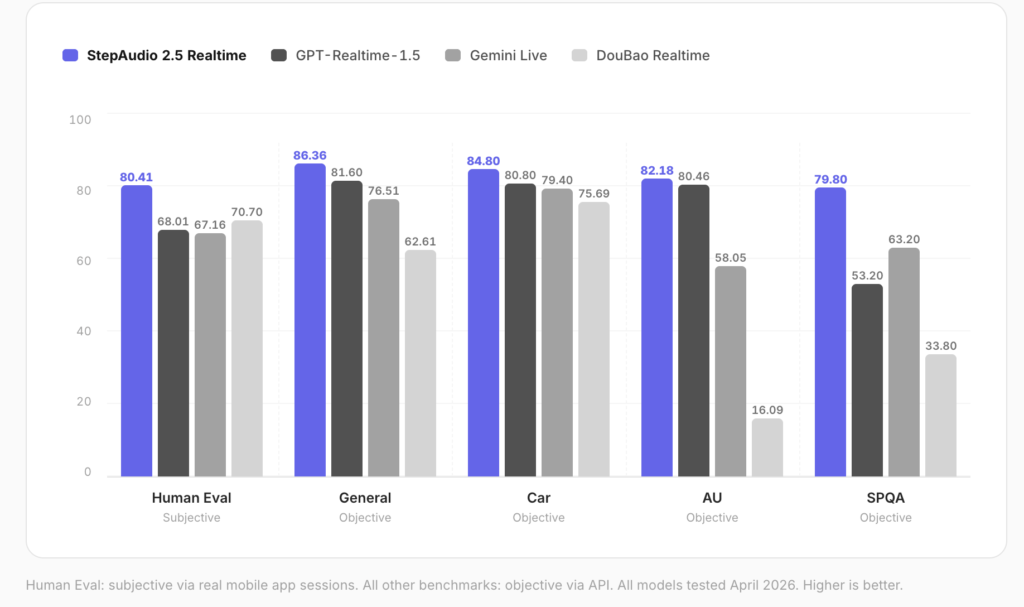
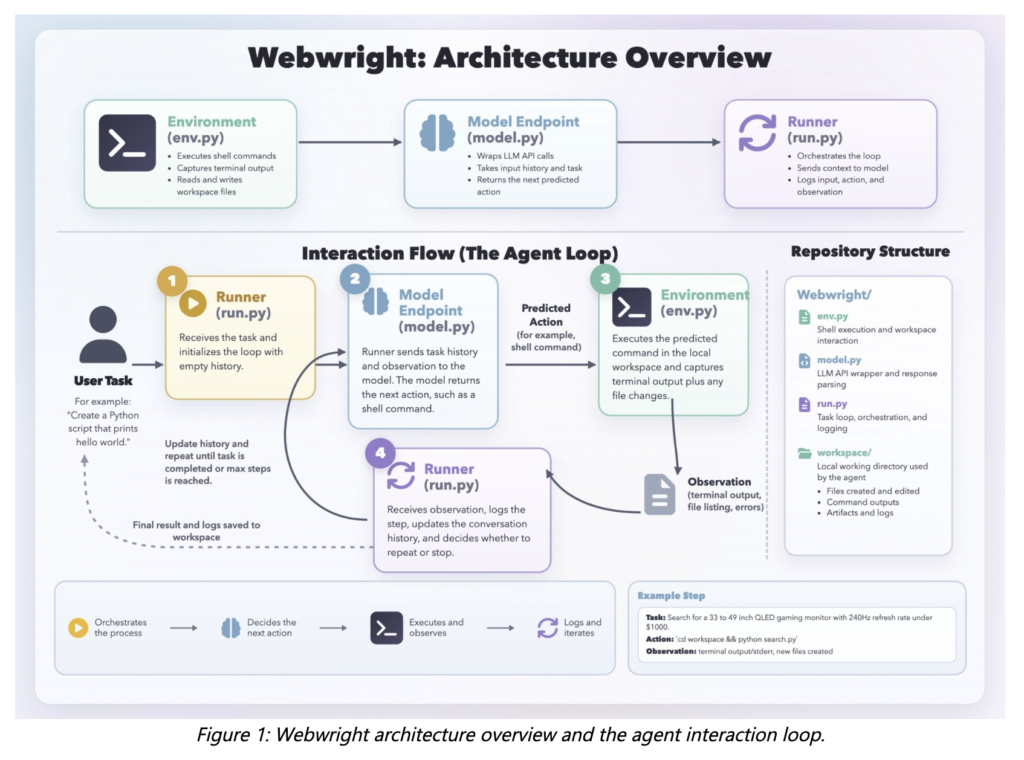
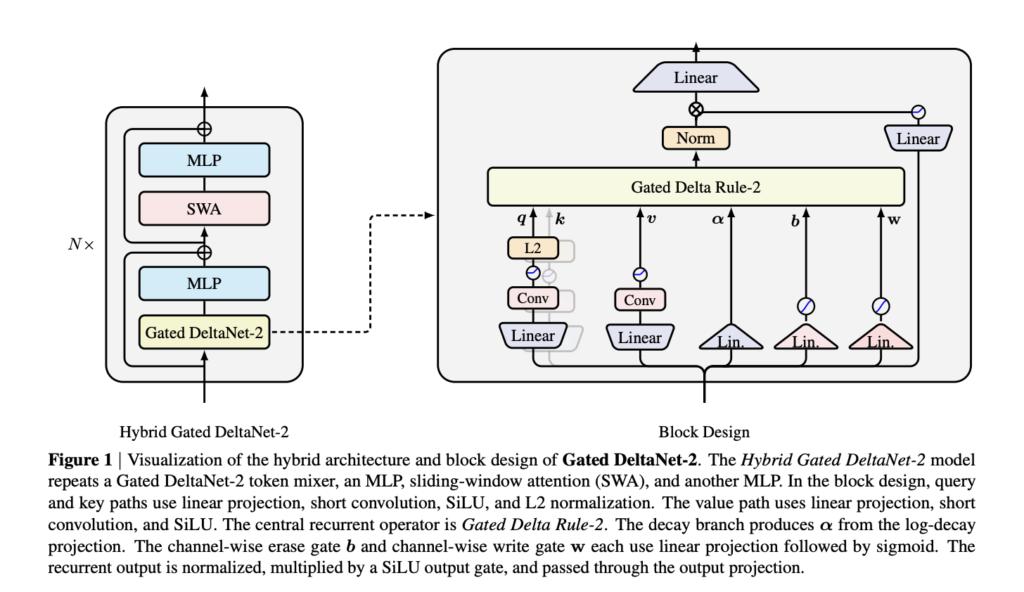
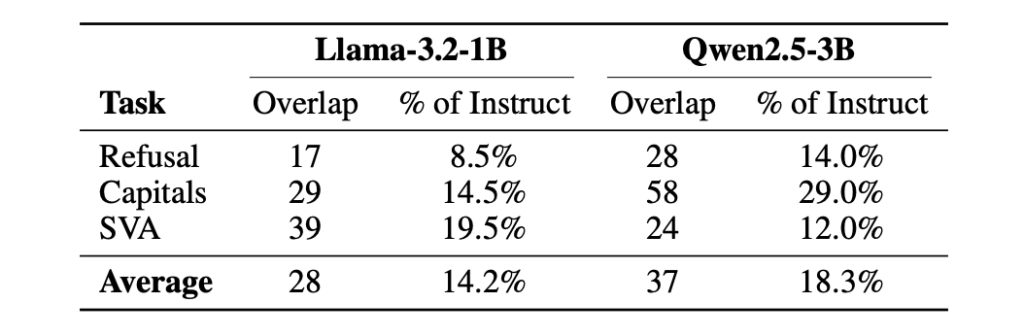
Build a Complete Langfuse Observability and Evaluation Pipeline for Tracing, Prompt Management, Scoring, and Experiments
In this tutorial, we implement the Langfuse (an open-source LLM engineering platform) pipeline for tracing, prompt management, scoring, datasets, and experiments. We build a complete workflow that works with either a real OpenAI key or a deterministic mock LLM, so we can understand every major Langfuse feature without depending on paid model access. We start […]