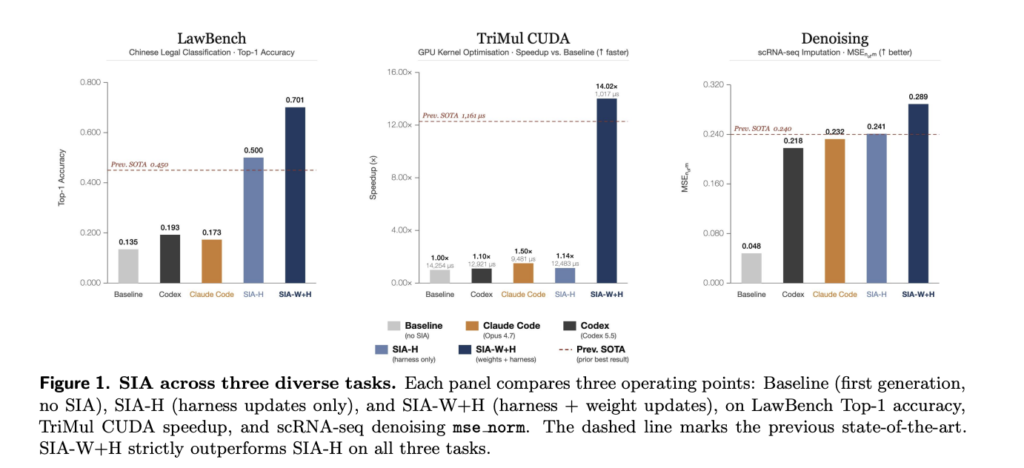
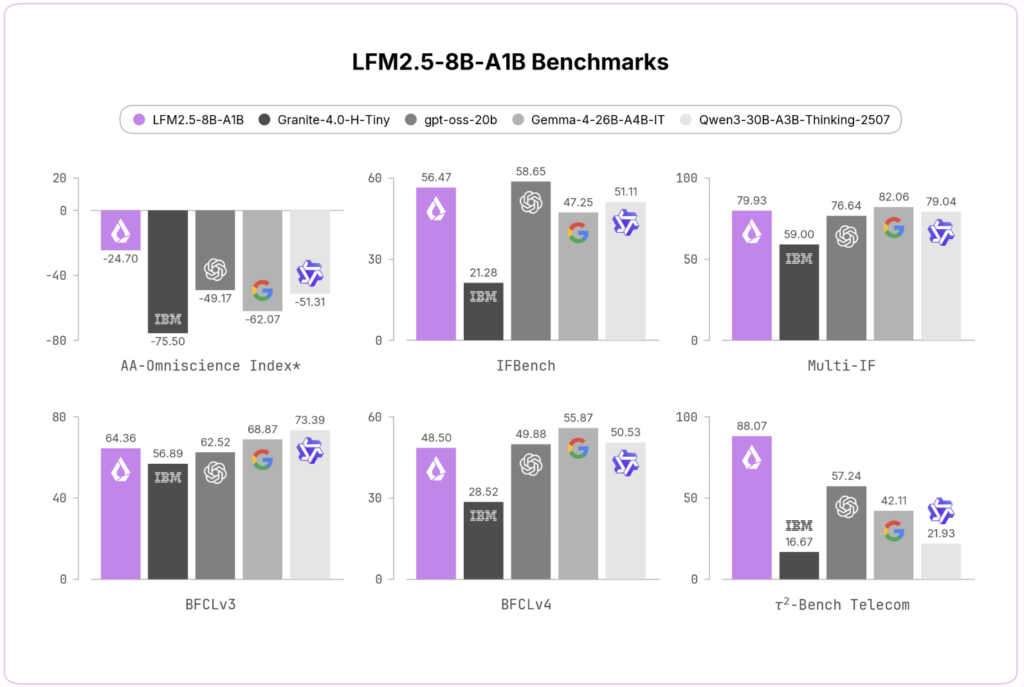
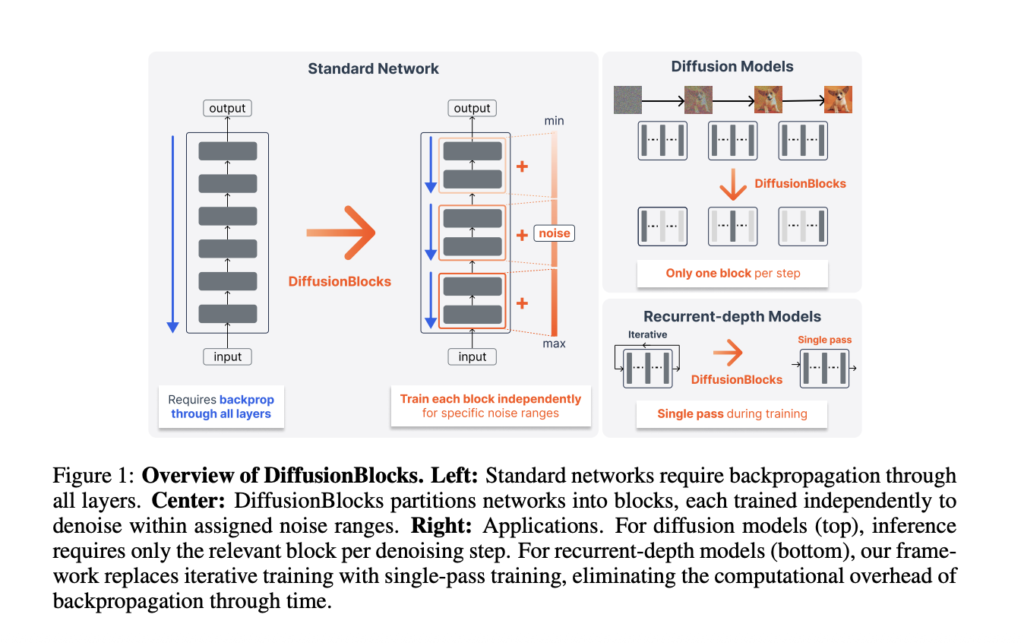
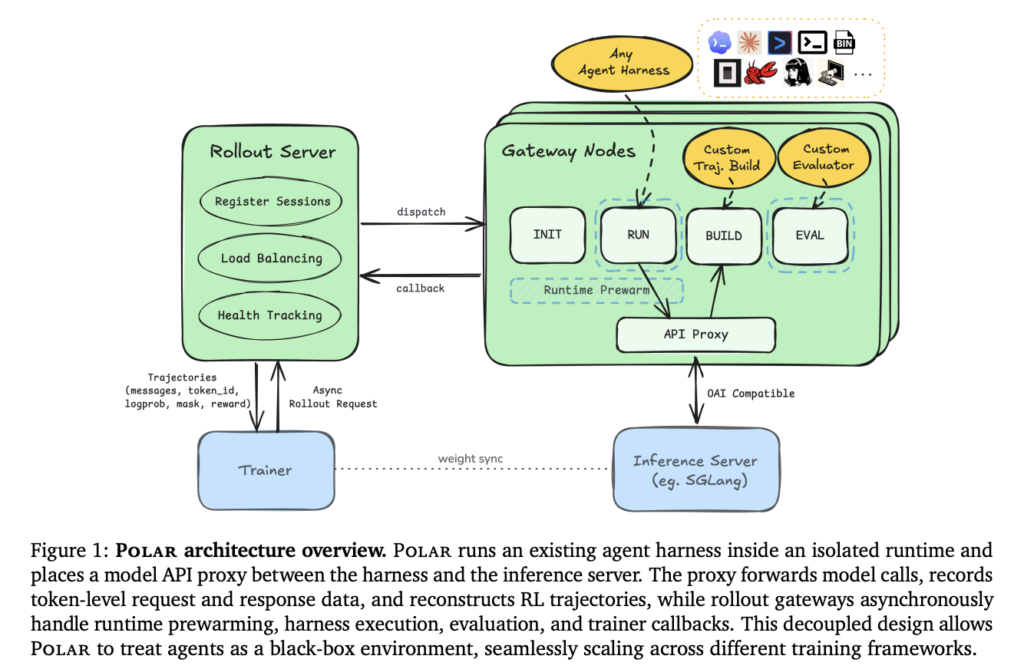
StepFun Releases Step 3.7 Flash: A 198B MoE Vision-Language Model for Coding Agents and Search Workflows
StepFun today released Step 3.7 Flash, a multimodal Mixture-of-Experts model targeting agentic use cases. It adds native vision input and improved tool-use reliability over Step 3.5 Flash. What is Step 3.7 Flash? Step 3.7 Flash is a 198B-parameter sparse Mixture-of-Experts (MoE) vision-language model. It pairs a 196B-parameter language backbone with a 1.8B-parameter vision encoder (ViT) […]