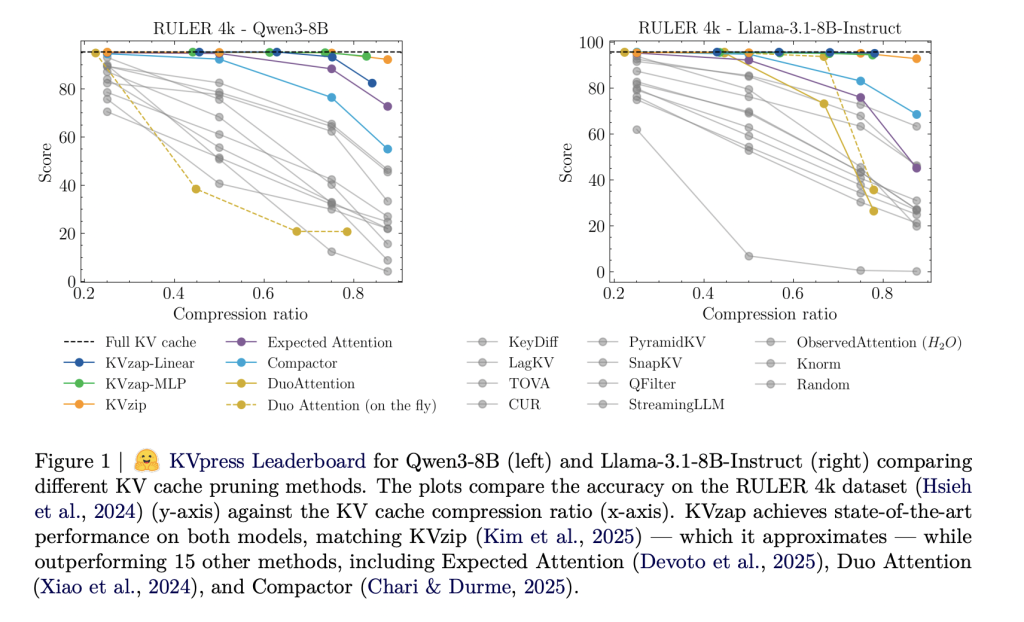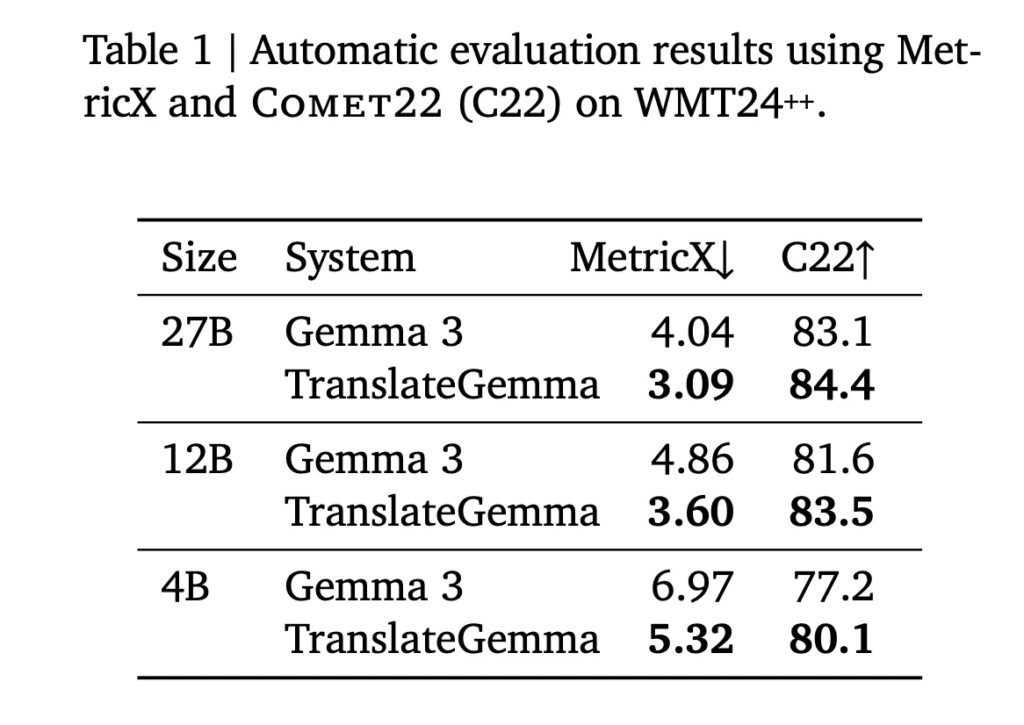
Google AI Releases TranslateGemma: A New Family of Open Translation Models Built on Gemma 3 with Support for 55 Languages
Google AI has released TranslateGemma, a suite of open machine translation models built on Gemma 3 and targeted at 55 languages. The family comes in 4B, 12B and 27B parameter sizes. It is designed to run across devices from mobile and edge hardware to laptops and a single H100 GPU or TPU instance in the […]