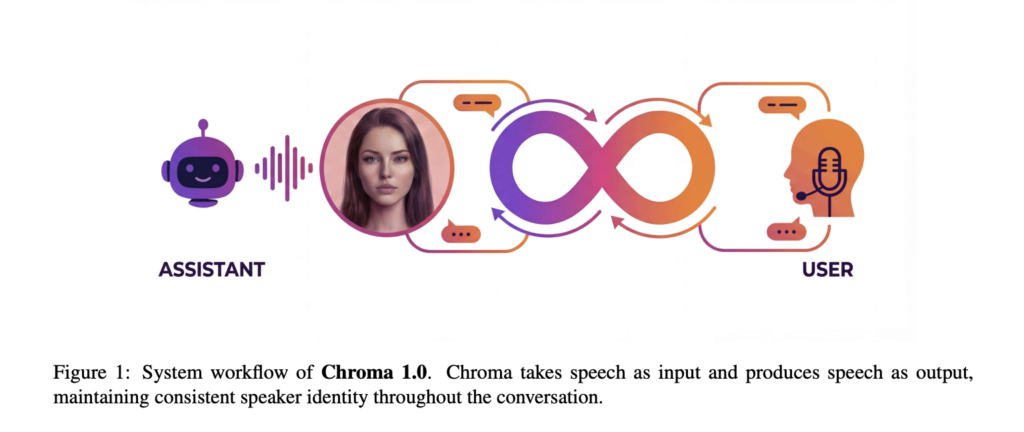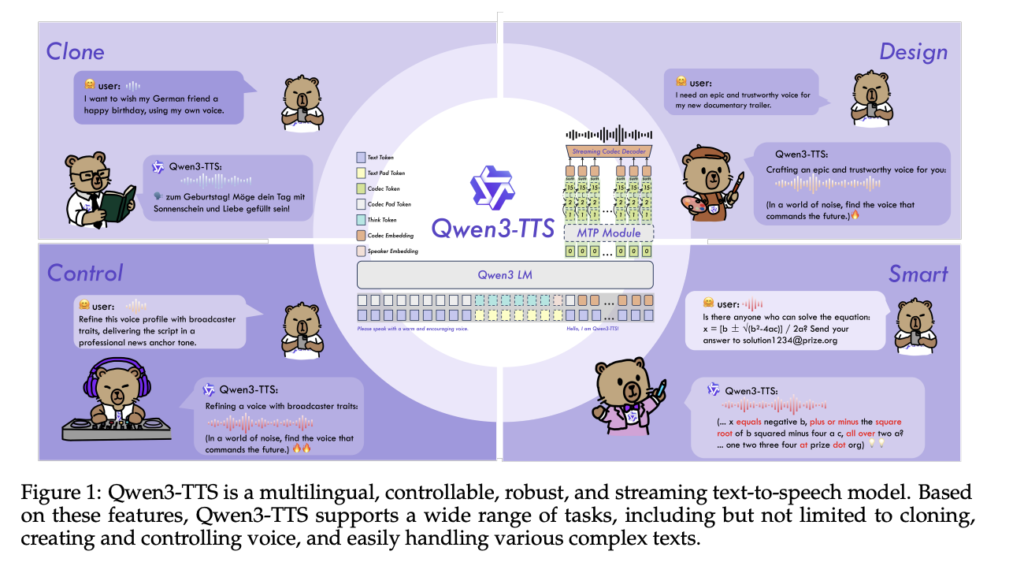
Qwen Researchers Release Qwen3-TTS: an Open Multilingual TTS Suite with Real-Time Latency and Fine-Grained Voice Control
Alibaba Cloud’s Qwen team has open-sourced Qwen3-TTS, a family of multilingual text-to-speech models that target three core tasks in one stack, voice clone, voice design, and high quality speech generation. https://arxiv.org/pdf/2601.15621v1 Model family and capabilities Qwen3-TTS uses a 12Hz speech tokenizer and 2 language model sizes, 0.6B and 1.7B, packaged into 3 main tasks. The […]