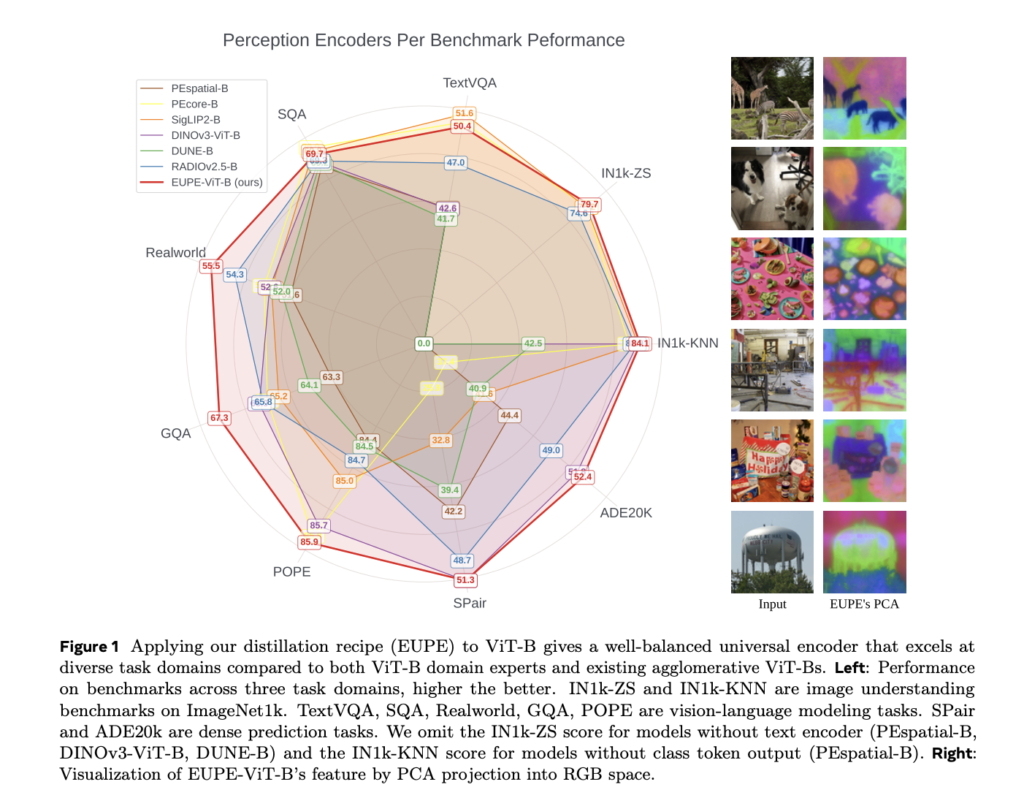
How Knowledge Distillation Compresses Ensemble Intelligence into a Single Deployable AI Model
Complex prediction problems often lead to ensembles because combining multiple models improves accuracy by reducing variance and capturing diverse patterns. However, these ensembles are impractical in production due to latency constraints and operational complexity. Instead of discarding them, Knowledge Distillation offers a smarter approach: keep the ensemble as a teacher and train a smaller student […]