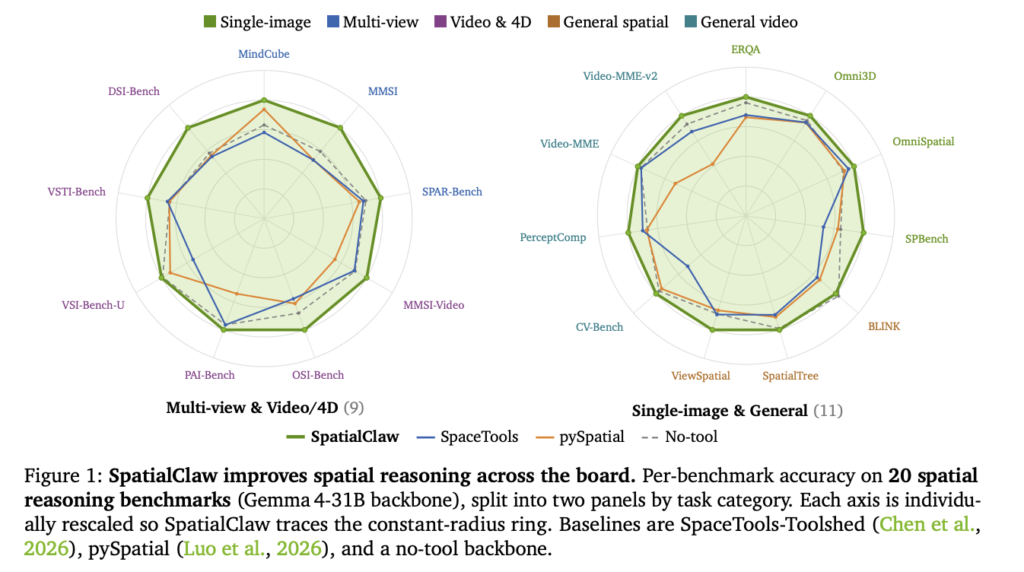
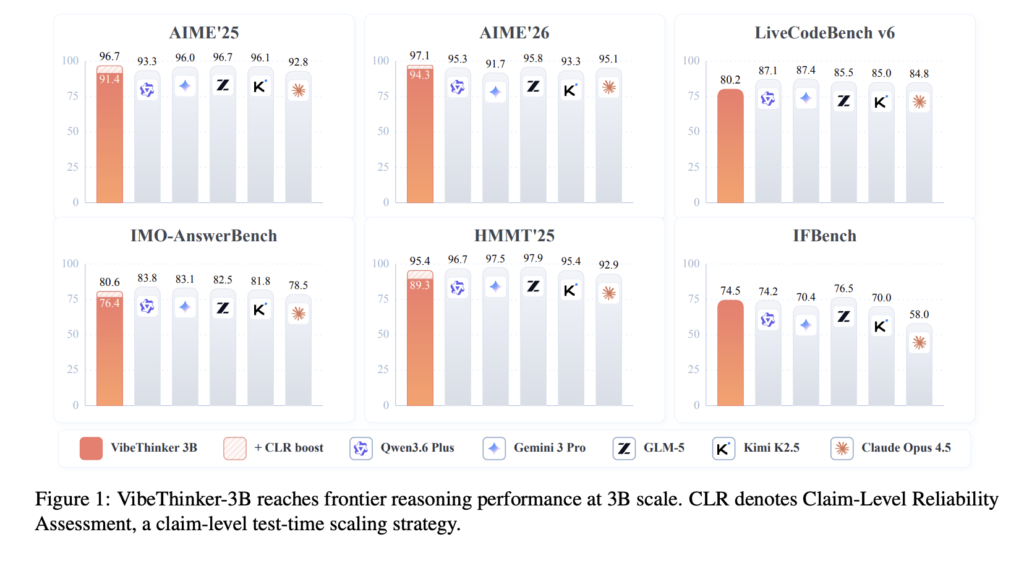
Prime Intellect Releases prime-rl 0.6.0 to Train Trillion-Parameter MoE Models on Agentic RL Workloads
Prime Intellect has released prime-rl version 0.6.0. The framework targets reinforcement learning on trillion-parameter Mixture-of-Experts (MoE) models. It focuses on heavy agentic workloads, like long-horizon software-engineering tasks. The research team trained GLM-5 on SWE tasks at up to 131k sequence length. Step times stayed under five minutes. The batch size was 256 rollouts. The run […]