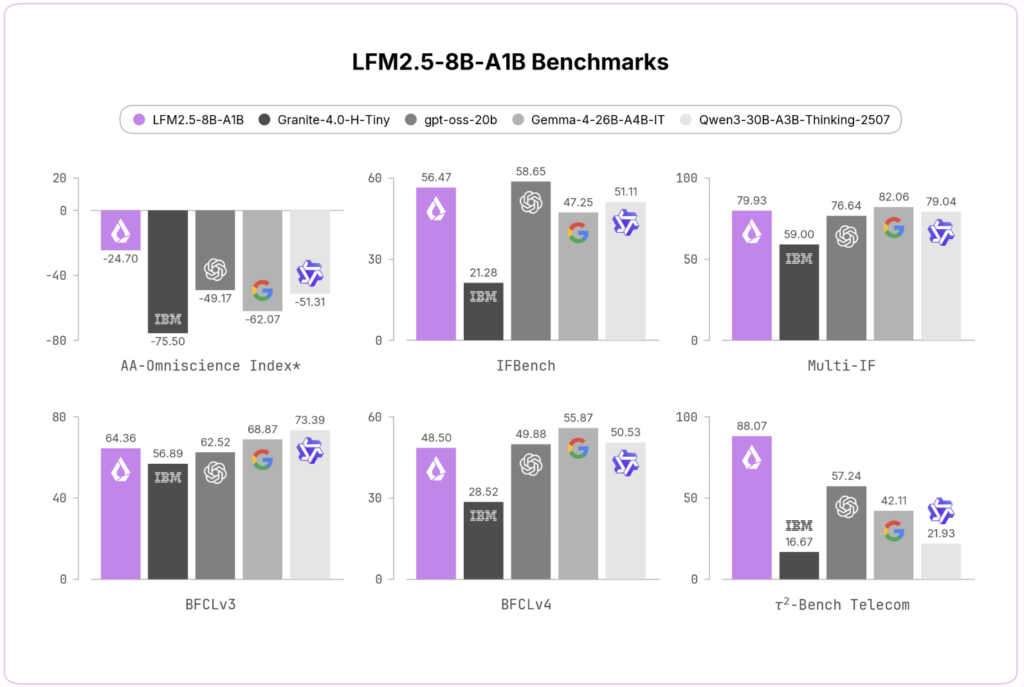
Genesis AI Releases Nyx, Quadrants, and Genesis World 1.0 Physics Platform for Scalable Robotics Foundation Model Evaluation
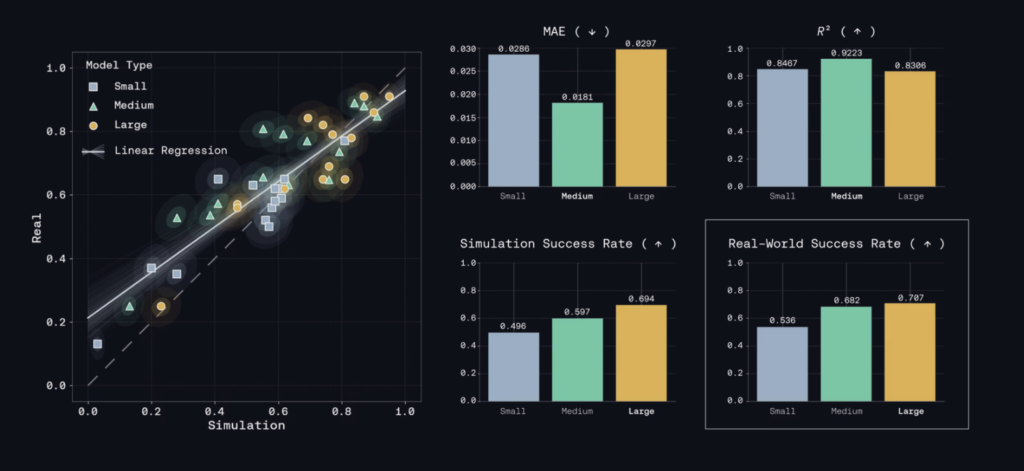
Genesis AI released Genesis World 1.0. The platform consists of four components: the Genesis World physics engine, Nyx (a real-time path-traced renderer), Quadrants (a Python-to-GPU compiler), and a simulation interface. It is designed to accelerate robotics foundation model development through simulation-based evaluation. Robotics model development has two bottlenecks: data and iteration speed. The field has […]