
Zyphra, the San Francisco-based AI lab behind the ZAYA1 model family, released ZAYA1-8B-Diffusion-Preview — a preview of its early work in diffusion-language models. The release demonstrates that an existing autoregressive language model can be converted into a discrete diffusion model with no systematic loss of evaluation performance, while delivering substantial inference speedups on AMD hardware.
https://www.zyphra.com/post/zaya1-8b-diffusion-preview
The Problem With Autoregressive Decoding
To understand why this matters, it helps to first understand how most language models generate text today. Standard large language models are autoregressive: they decode one token at a time in sequence. For each new token, the attention mechanism has to look back over all previously generated tokens and load their stored representations — called the KV-cache — from GPU memory. Crucially, because every user in a batch has a different history of tokens, each user’s KV-cache must be loaded separately and cannot be shared across requests.
This creates a bottleneck. When the GPU spends more time moving data from memory than performing actual computation, the system becomes memory-bandwidth bound rather than compute-bound. This limits how efficiently modern GPU hardware — which has been scaling compute FLOPs faster than memory bandwidth — can be used during inference.
Diffusion offers an alternative. Instead of generating one token at a time, a diffusion model generates multiple drafts of N tokens simultaneously and iterates this drafting process multiple times. Because all N tokens in the block share the same KV-cache, the operation shifts from memory-bandwidth bound to compute-bound, which means the GPU can be utilized more efficiently. In ZAYA1-8B-Diffusion-Preview specifically, the model performs a single-step transformation from mask to token for each token in the block — meaning it directly predicts the unmasked token in one step rather than iteratively denoising.
Converting Autoregression to Diffusion Without Training From Scratch
Training a diffusion language model from scratch is technically difficult, and there are few established recipes for doing so. Zyphra team offers two reasons for preferring conversion over training from scratch: first, it is simply hard, with few known recipes; second, there is no advantage to training in diffusion-mode because training is already compute-bound — the memory-bandwidth bottleneck that diffusion solves only appears at inference time. This means all the benefits of diffusion are inference-time benefits, and an existing pretraining stack can be reused as-is.
Building on the TiDAR recipe, Zyphra took the ZAYA1-8B-base checkpoint and performed an additional 600 billion tokens of diffusion-conversion mid-training at a 32k context length, followed by 500 billion tokens of native context extension to 128k, and then a diffusion supervised fine-tuning (SFT) phase.
ZAYA1-8B-Diffusion-Preview is the first MoE diffusion model converted from an autoregressive LLM, and the first diffusion-language model to be trained on AMD GPUs. Zyphra reports minimal evaluation degradation compared to the base autoregressive checkpoint, with gains on some benchmarks such as LCB-v6. They attribute this partly to improved mid-training datasets and partly to the greater expressivity of diffusion-style within-block non-causal inference compared to causal autoregression.
How the Diffusion Sampler Works
During inference, ZAYA1-8B-Diffusion-Preview generates a draft of 16 tokens simultaneously. A fraction of these tokens are accepted based on a sampling criterion borrowed from speculative decoding. The key advantage here is that the same model acts as both speculator and verifier within a single forward pass, which removes the overhead associated with running two separate models as in traditional methods like EAGLE or dFlash. In heavily memory-bandwidth-bound regimes, almost all accepted tokens represent free speedup over autoregressive decoding — the GPU is already loaded and the extra tokens cost very little additional compute.
Zyphra team reports two samplers with different speed-quality trade-offs:
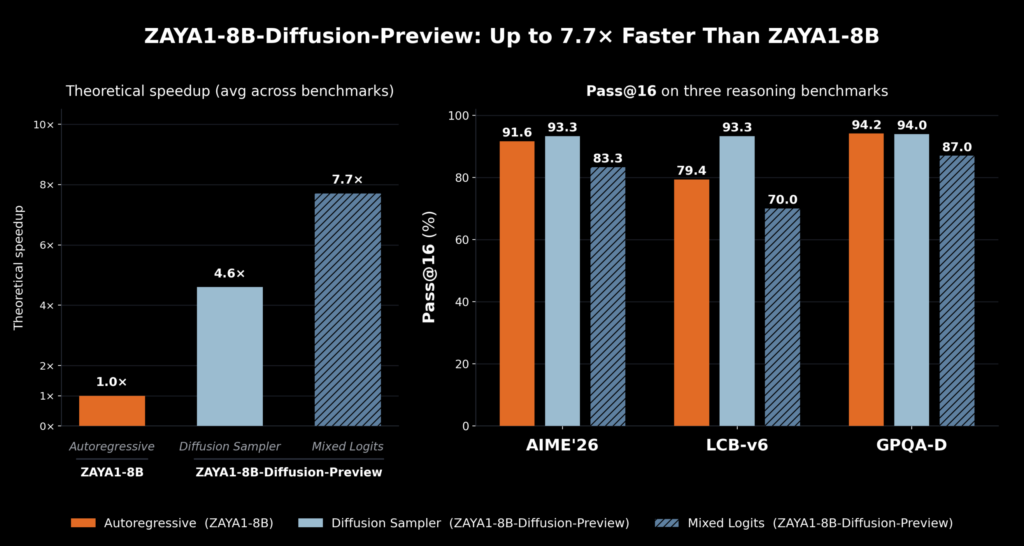
Lossless diffusion sampler: Uses the standard speculative decoding acceptance criterion of min(1, p(x)/q(x)), where p is the autoregressive model’s logit distribution and q is the diffusion model’s distribution. Upon rejection, the next token is sampled from the residual distribution of p(x)-q(x). This sampler achieves a 4.6x speedup with no systematic evaluation degradation.
Logit-mixing sampler: First mixes the logits from the diffusion speculator and the autoregressive model, then uses the averaged distribution for verification. This improves acceptance rates because the verification logits are closer to the diffusion logits, but has some impact on quality. This sampler achieves a 7.7x speedup. The trade-off between speed and quality can be chosen at runtime.
One important caveat on these numbers: because ZAYA1-8B-Diffusion-Preview is a base mid-train checkpoint that has not yet undergone RL training, Zyphra uses pass@ evaluations rather than standard accuracy benchmarks to better represent the model’s ultimate potential after RL training. Readers comparing these figures to other models’ reported benchmarks should keep this in mind.
Zyphra team also notes that the speedups observed from diffusion are higher than those from alternative methods such as multi-token prediction (MTP) and various speculative decoding strategies such as EAGLE3. Since TiDAR-style diffusion models utilize a single forward pass only, acceptance rates comparable to dFlash still yield substantial speedups.
https://www.zyphra.com/post/zaya1-8b-diffusion-preview
Architecture Details
ZAYA1-8B-Diffusion-Preview is a single-step speculative diffusion model that uses order constrained generation which means the diffusion model is only capable of generating tokens in a contiguous subsequence starting from the prefix. This constraint increases training stability dramatically compared to unconstrained mask diffusion objectives or set block decoding, and was a primary reason Zyphra built on the TiDAR recipe.
The model uses ZAYA1-8B’s existing CCA attention variant from Zyphra. CCA dramatically reduces prefill FLOPs in attention, which is directly beneficial for diffusion because diffusion converts decoding into a prefill-like operation. This means CCA lets the model diffuse more tokens in parallel before hitting compute limits.
More specifically, the architecture uses CCGQA with a 4:1 ratio between query heads and key heads. One design choice behind this was deliberately avoiding MLA (Multi-Head Latent Attention), whose high arithmetic intensity was seen as a mismatch compared to CCGQA. Since block diffusion accesses the same cache, arithmetic intensity scales with block size and with the number of blocks per forward pass. On AMD MI300x hardware in bf16, the system supports roughly three block-sized proposals per single forward pass; on MI355x, this rises to approximately five. CCGQA also operates at 2x compression, which allowed Zyphra to afford the additional training FLOPs associated with TiDAR mid-training. The greater VRAM capacity of AMD GPU hardware further enabled more efficient diffusion training overall.
In practice, attaining the theoretical speedups is more challenging because diffusion carries additional operational overhead and the inference stack for diffusion models is substantially less optimized than the mature tooling available for autoregressive inference.
Marktechpost’s Visual Explainer
#zaya1dg,#zaya1dg *{box-sizing:border-box!important;margin:0!important;padding:0!important}
#zaya1dg p:empty,#zaya1dg hr,#zaya1dg del,#zaya1dg s,#zaya1dg br{display:none!important}
#zaya1dg{
background:#111!important;
color:#e0e0e0!important;
font-family:’Courier New’,Courier,monospace!important;
border:1px solid #76B900!important;
border-radius:6px!important;
overflow:hidden!important;
width:100%!important;
max-width:760px!important;
display:block!important;
}
/* HEADER */
#zaya1dg .dg-head{
background:#0a0a0a!important;
border-bottom:1px solid #76B900!important;
padding:12px 18px!important;
display:flex!important;
align-items:center!important;
justify-content:space-between!important;
}
#zaya1dg .dg-head-label{
font-size:10px!important;
letter-spacing:2px!important;
color:#76B900!important;
text-transform:uppercase!important;
font-weight:700!important;
}
#zaya1dg .dg-head-tag{
font-size:10px!important;
background:#76B900!important;
color:#111!important;
padding:3px 9px!important;
border-radius:2px!important;
font-weight:700!important;
letter-spacing:1px!important;
}
/* PROGRESS */
#zaya1dg .dg-prog{
height:2px!important;
background:#1c1c1c!important;
width:100%!important;
display:block!important;
}
#zaya1dg .dg-prog-bar{
height:2px!important;
background:#76B900!important;
transition:width .3s!important;
display:block!important;
}
/* SLIDE VIEWPORT */
#zaya1dg .dg-viewport{
overflow:hidden!important;
width:100%!important;
position:relative!important;
}
#zaya1dg .dg-track{
display:flex!important;
transition:transform .35s cubic-bezier(.4,0,.2,1)!important;
width:100%!important;
align-items:flex-start!important;
}
/* EACH SLIDE */
#zaya1dg .dg-slide{
min-width:100%!important;
width:100%!important;
flex-shrink:0!important;
overflow-y:auto!important;
overflow-x:hidden!important;
height:390px!important;
padding:22px 22px 16px 22px!important;
display:block!important;
}
/* SLIDE TYPOGRAPHY */
#zaya1dg .dg-slide-num{
display:block!important;
font-size:10px!important;
color:#76B900!important;
letter-spacing:2px!important;
text-transform:uppercase!important;
margin-bottom:10px!important;
}
#zaya1dg .dg-slide-title{
font-size:15px!important;
font-weight:700!important;
color:#fff!important;
line-height:1.35!important;
border-left:3px solid #76B900!important;
padding-left:10px!important;
margin-bottom:14px!important;
display:block!important;
}
#zaya1dg .dg-text{
font-size:12.5px!important;
line-height:1.7!important;
color:#bbb!important;
display:block!important;
margin-bottom:10px!important;
}
/* KV TABLE */
#zaya1dg .dg-kv{
background:#0d0d0d!important;
border:1px solid #222!important;
border-radius:4px!important;
overflow:hidden!important;
margin-top:12px!important;
display:block!important;
}
#zaya1dg .dg-kv-row{
display:flex!important;
align-items:flex-start!important;
border-bottom:1px solid #1a1a1a!important;
padding:8px 12px!important;
gap:10px!important;
}
#zaya1dg .dg-kv-row:last-child{border-bottom:none!important}
#zaya1dg .dg-kv-k{
font-size:10px!important;
color:#76B900!important;
text-transform:uppercase!important;
letter-spacing:1px!important;
min-width:96px!important;
flex-shrink:0!important;
padding-top:1px!important;
font-weight:700!important;
}
#zaya1dg .dg-kv-v{
font-size:12px!important;
color:#ccc!important;
line-height:1.5!important;
}
/* METRIC CARDS */
#zaya1dg .dg-metrics{
display:grid!important;
grid-template-columns:1fr 1fr!important;
gap:10px!important;
margin-top:12px!important;
}
#zaya1dg .dg-metric{
background:#0d0d0d!important;
border:1px solid #76B900!important;
border-radius:4px!important;
padding:14px 12px!important;
text-align:center!important;
display:block!important;
}
#zaya1dg .dg-metric-num{
font-size:30px!important;
font-weight:700!important;
color:#76B900!important;
display:block!important;
line-height:1!important;
margin-bottom:6px!important;
}
#zaya1dg .dg-metric-sub{
font-size:10px!important;
color:#888!important;
text-transform:uppercase!important;
letter-spacing:1px!important;
line-height:1.5!important;
display:block!important;
}
/* COMPARE GRID */
#zaya1dg .dg-compare{
display:grid!important;
grid-template-columns:1fr 1fr!important;
gap:10px!important;
margin-top:12px!important;
}
#zaya1dg .dg-col{
background:#0d0d0d!important;
border:1px solid #222!important;
border-radius:4px!important;
padding:12px!important;
display:block!important;
}
#zaya1dg .dg-col.green{border-color:#76B900!important}
#zaya1dg .dg-col-head{
font-size:10px!important;
text-transform:uppercase!important;
letter-spacing:1.5px!important;
font-weight:700!important;
margin-bottom:8px!important;
display:block!important;
color:#666!important;
}
#zaya1dg .dg-col.green .dg-col-head{color:#76B900!important}
#zaya1dg .dg-col-item{
font-size:11.5px!important;
color:#bbb!important;
line-height:1.5!important;
display:block!important;
padding:4px 0!important;
border-bottom:1px solid #1a1a1a!important;
}
#zaya1dg .dg-col-item:last-child{border-bottom:none!important}
/* STEPS */
#zaya1dg .dg-steps{
margin-top:12px!important;
display:block!important;
}
#zaya1dg .dg-step{
display:flex!important;
gap:12px!important;
margin-bottom:0!important;
}
#zaya1dg .dg-step-l{
display:flex!important;
flex-direction:column!important;
align-items:center!important;
flex-shrink:0!important;
}
#zaya1dg .dg-step-dot{
width:22px!important;
height:22px!important;
border-radius:50%!important;
background:#76B900!important;
color:#111!important;
font-size:10px!important;
font-weight:700!important;
display:flex!important;
align-items:center!important;
justify-content:center!important;
flex-shrink:0!important;
}
#zaya1dg .dg-step-line{
width:1px!important;
background:#2a2a2a!important;
flex:1!important;
min-height:12px!important;
display:block!important;
}
#zaya1dg .dg-step-r{
padding-bottom:14px!important;
flex:1!important;
}
#zaya1dg .dg-step-r b{
display:block!important;
font-size:12.5px!important;
color:#fff!important;
margin-bottom:2px!important;
font-weight:700!important;
}
#zaya1dg .dg-step-r span{
font-size:11.5px!important;
color:#999!important;
line-height:1.5!important;
display:block!important;
}
/* CALLOUT */
#zaya1dg .dg-callout{
background:#0c1400!important;
border-left:3px solid #76B900!important;
padding:10px 14px!important;
margin-top:12px!important;
font-size:12px!important;
color:#aaa!important;
line-height:1.6!important;
border-radius:0 3px 3px 0!important;
display:block!important;
}
#zaya1dg .dg-callout b{color:#76B900!important}
/* PILLS */
#zaya1dg .dg-pills{
display:flex!important;
flex-wrap:wrap!important;
gap:7px!important;
margin-top:12px!important;
}
#zaya1dg .dg-pill{
border:1px solid #333!important;
border-radius:20px!important;
padding:4px 11px!important;
font-size:11px!important;
color:#999!important;
background:#141414!important;
display:inline-block!important;
}
#zaya1dg .dg-pill.g{
border-color:#76B900!important;
color:#76B900!important;
background:#0a1100!important;
}
/* NAV */
#zaya1dg .dg-nav{
background:#0a0a0a!important;
border-top:1px solid #1e1e1e!important;
padding:10px 18px!important;
display:flex!important;
align-items:center!important;
justify-content:space-between!important;
}
#zaya1dg .dg-dots{
display:flex!important;
gap:6px!important;
align-items:center!important;
}
#zaya1dg .dg-dot{
width:6px!important;
height:6px!important;
border-radius:50%!important;
background:#333!important;
border:none!important;
cursor:pointer!important;
padding:0!important;
transition:all .2s!important;
display:inline-block!important;
}
#zaya1dg .dg-dot.on{
background:#76B900!important;
width:18px!important;
border-radius:3px!important;
}
#zaya1dg .dg-btn{
background:transparent!important;
border:1px solid #2e2e2e!important;
color:#aaa!important;
font-family:’Courier New’,Courier,monospace!important;
font-size:11px!important;
padding:6px 14px!important;
border-radius:3px!important;
cursor:pointer!important;
letter-spacing:1px!important;
transition:all .2s!important;
}
#zaya1dg .dg-btn:hover{border-color:#76B900!important;color:#76B900!important}
#zaya1dg .dg-btn:disabled{opacity:.25!important;cursor:default!important}
/* MOBILE */
@media(max-width:640px){
#zaya1dg .dg-slide{padding:16px 14px 14px 14px!important;height:420px!important}
#zaya1dg .dg-slide-title{font-size:13px!important}
#zaya1dg .dg-text{font-size:11.5px!important}
#zaya1dg .dg-metrics{grid-template-columns:1fr 1fr!important}
#zaya1dg .dg-compare{grid-template-columns:1fr!important}
#zaya1dg .dg-metric-num{font-size:24px!important}
#zaya1dg .dg-kv-k{min-width:80px!important}
#zaya1dg .dg-nav{padding:8px 12px!important}
#zaya1dg .dg-btn{font-size:10px!important;padding:5px 10px!important}
#zaya1dg .dg-head{padding:10px 14px!important}
}
■ Marktechpost Guide
ZAYA1-8B-Diffusion-Preview
01 / 08 — Overview
What is ZAYA1-8B-Diffusion-Preview?
Zyphra released ZAYA1-8B-Diffusion-Preview on May 14, 2026. It converts an existing autoregressive MoE language model into a discrete diffusion model with no systematic loss in evaluation performance, delivering up to 7.7x inference speedup on AMD hardware.
Instead of one token at a time, it generates 16 tokens simultaneously using a single-step transformation from mask to token.
ReleasedMay 14, 2026 — San Francisco
ByZyphra
Base modelZAYA1-8B (autoregressive MoE)
HardwareAMD MI300x / MI355x
First of kindFirst MoE diffusion model converted from an AR LLM; first diffusion-LM trained on AMD
02 / 08 — The Problem
Why Autoregressive Decoding Creates a Bottleneck
Standard LLMs are autoregressive: one token per step. For every new token, the model loads each user’s KV-cache from GPU memory separately. Since every user in a batch has a different token history, caches cannot be shared across requests.
This makes decoding memory-bandwidth bound in many serving scenarios — the GPU waits on data transfers instead of computing. Modern GPUs scale FLOPs faster than memory bandwidth, making this gap worse over time.
For engineers: Memory-bandwidth bound = GPU compute units sit idle waiting for HBM data. Compute-bound = GPU is fully utilized. Diffusion targets this by sharing one KV-cache load across N tokens.
03 / 08 — The Solution
How Diffusion Removes the Bottleneck
A diffusion model generates multiple drafts of N tokens simultaneously. All N tokens in a block share the same KV-cache — one cache load regardless of block size. This shifts the workload from memory-bandwidth bound to compute-bound.
Autoregressive
1 token per pass
Separate KV-cache per user
Memory-bandwidth bound
Low GPU utilization
Diffusion (ZAYA1)
16 tokens per pass
Shared KV-cache per block
Compute-bound
Up to 7.7x speedup
04 / 08 — Training Pipeline
How the Model Was Converted
Training from scratch is hard and offers no benefit since training is already compute-bound. The bottleneck only appears at inference. Zyphra converts via mid-training using the TiDAR recipe, reusing the existing pretraining stack.
1
ZAYA1-8B-base checkpointPretrained autoregressive MoE base model
2
Diffusion mid-training — 600B tokens @ 32kTiDAR recipe applied to convert to discrete diffusion
3
Context extension — 500B tokens @ 128kNatively extends context length to 128k tokens
4
Diffusion SFT phaseSupervised fine-tuning in diffusion mode
Total: 1.1 trillion tokens of additional mid-training on top of ZAYA1-8B pretraining.
05 / 08 — Inference
Two Samplers: Speed vs. Quality
The model drafts 16 tokens per step. A fraction are accepted via a sampling criterion, similar to speculative decoding, but the same model acts as both speculator and verifier in a single forward pass — no separate draft model needed, unlike EAGLE or dFlash.
4.6x
Lossless SamplerNo systematic eval lossmin(1, p(x)/q(x))
7.7x
Logit-Mixing SamplerSome quality trade-offMixes AR + diffusion logits
Note: On rejection in the lossless sampler, next token is sampled from residual distribution p(x)—q(x). Speed/quality trade-off is selectable at runtime.
06 / 08 — Architecture
Architecture Details
A single-step speculative diffusion model using order constrained generation — it only generates tokens in a contiguous subsequence starting from the prefix. This increases training stability vs. unconstrained mask diffusion or set block decoding.
AttentionZyphra’s CCA attention — reduces prefill FLOPs, enables more parallel tokens before compute limit
CCGQA4:1 query-to-key heads; 2x compression; avoids MLA’s high arithmetic intensity
MI300x (bf16)~3 block-sized proposals per forward pass
MI355x~5 block-sized proposals per forward pass
07 / 08 — Results
Benchmark Results & Comparisons
Minimal evaluation degradation vs. the base AR checkpoint. Gains on benchmarks including LCB-v6, attributed to improved mid-training datasets and greater expressivity of diffusion-style within-block non-causal inference.
ZAYA1 Diffusion: 4.6x—7.7x
MTP: lower
EAGLE3: lower
dFlash: lower net speedup
Important: Evaluations use pass@ metrics, not standard accuracy benchmarks — because this is a base mid-train checkpoint pre-RL training. Do not compare directly to standard benchmark scores from other models.
08 / 08 — Implications
Why This Matters for AI Engineers
The deeper implication is for RL training: on-policy rollouts — model-generated sequences used during reinforcement learning — are expensive. Faster, compute-optimal generation lowers rollout cost, making RL and test-time compute scaling more practical.
For MLEsCompute-bound inference = better GPU utilization at serving time
For RL teamsCheaper on-policy rollouts = more RL iterations at same hardware budget
For architectsCCA + CCGQA co-designed for diffusion from the start — not bolted on
AccessZAYA1-8B-base on Hugging Face (Zyphra). Diffusion inference stack is early-stage.
← PREV
NEXT →
(function(){
var N=8,c=0;
var track=document.getElementById(‘dgTrack’);
var dots=document.getElementById(‘dgDots’);
var prev=document.getElementById(‘dgPrev’);
var next=document.getElementById(‘dgNext’);
var bar=document.getElementById(‘dgBar’);
for(var i=0;i