
While recent breakthroughs in AI reasoning have largely been driven by massive scale, pouring in billions of parameters to cross complex cognitive thresholds—VibeThinker-3B is charting a completely different path.
Created by researchers from Sina Weibo Inc (China), this 3-billion-parameter model proves that efficiency can punch far above its weight class. Released under an open-source MIT license, VibeThinker-3B matches the performance of models hundreds of times its size on verifiable tasks like mathematics, coding, and STEM disciplines.
What is VibeThinker-3B
VibeThinker-3B is a compact dense model built on the Qwen2.5-Coder-3B base. It is post-trained, not pretrained from scratch. The research team applies supervised fine-tuning, reinforcement learning, and self-distillation on top.
The training framework continues the Spectrum-to-Signal Principle (SSP) from the earlier VibeThinker-1.5B. SFT (Supervised Fine-Tuning) builds a broad space of valid reasoning paths, the ‘Spectrum.’ RL then amplifies the correct paths, the ‘Signal.’
The model targets one job: reasoning where a verifier can confirm the answer. The research team recommends larger general models for open-domain knowledge tasks. VibeThinker-3B is a specialist by design.
It runs on standard stacks. The model weights require transformers>=4.54.0. For faster inference it recommends vLLM==0.10.1 or SGLang>=0.4.9.post6. The BF16 weights are roughly 6 GB, small enough for a single GPU.
https://arxiv.org/pdf/2606.16140v1
Benchmark
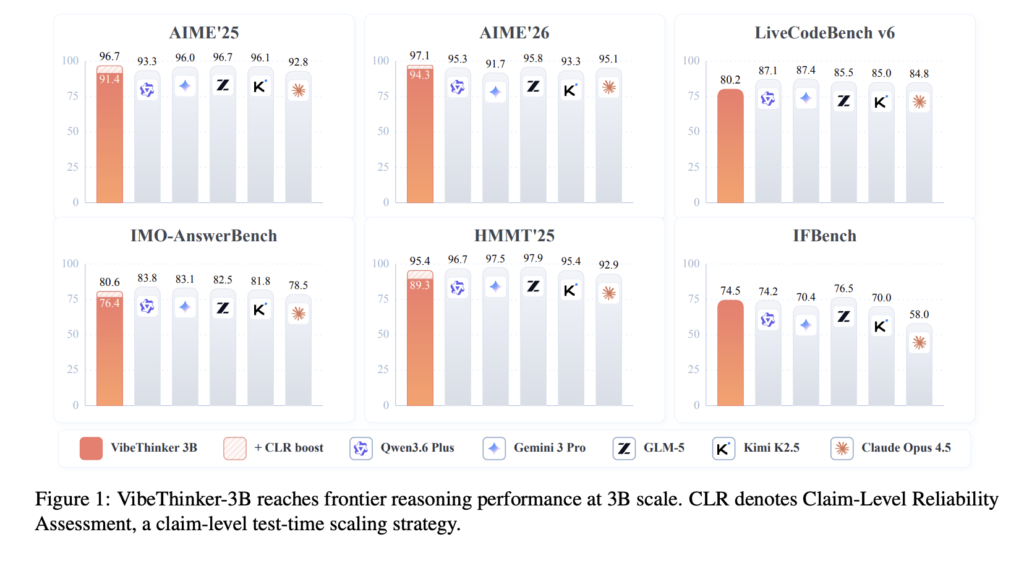
On AIME26, VibeThinker-3B scores 94.3. According to the research paper, this is comparable to DeepSeek V3.2 (671B) and Kimi K2.5 (1T).
On LiveCodeBench v6, it reaches 80.2 Pass@1. On OJBench, another code benchmark, it scores 38.6, below the largest models. On HMMT25 it scores 89.3, and on BruMO25 it reaches 93.8. On IMO-AnswerBench, a 400-problem IMO-level set, it scores 76.4.
The table below compares it against much larger reasoning models. The ‘+CLR’ row uses test-time scaling. It stands for Claim-Level Reliability Assessment
ModelParamsAIME26HMMT25IMO-AnsLCBv6GPQA-DVibeThinker-3B3B94.389.376.480.270.2VibeThinker-3B +CLR3B97.195.480.6—72.9GPT-OSS (high)120B93.290.075.681.980.1DeepSeek V3.2671B94.290.278.380.882.4GLM-5744B95.897.982.585.586.0Kimi K2.51T93.395.481.885.087.6Source: VibeThinker-3B Technical Report, Table 2. GPQA-D is GPQA-Diamond.
The pattern is consistent. On verifiable math and code, the 3B model sits near the top cluster. On GPQA-Diamond, a knowledge-heavy benchmark, the gap to large models stays visible.
The research team also ran an out-of-distribution coding test. It used recent LeetCode weekly and biweekly contests, from Apr 25 to May 31, 2026. The model passed 123 of 128 first-attempt Python submissions. That is a 96.1% acceptance rate on unseen problems.
Inside the Spectrum-to-Signal Pipeline
The post-training pipeline runs in four stages. Each one targets a different weakness of small reasoning models.
First comes curriculum-based two-stage SFT. Stage 1 covers math, code, STEM, dialogue, and instruction following broadly. Stage 2 shifts to harder, longer-horizon samples filtered by reasoning length and difficulty. Diversity-Exploring Distillation preserves multiple valid solution paths through both stages.
Second comes multi-domain Reasoning RL. The research team reuses MaxEnt-Guided Policy Optimization (MGPO). MGPO weights prompts near the model’s current capability boundary, where correct and incorrect rollouts coexist. Training runs sequentially across Math, Code, and STEM.
A notable detail: VibeThinker-3B drops progressive context expansion. The research team found high-truncation warm-up hurt long reasoning at this scale. So RL uses a single 64K long-context window throughout.
Math RL adds a Long2Short stage. It redistributes reward among correct trajectories by length. Shorter correct answers get higher reward, longer ones lower, with the group mean unchanged. The goal is fewer redundant tokens without losing accuracy.
Third, Offline Self-Distillation merges the RL checkpoints back into one student model. Fourth, Instruct RL improves instruction adherence. That stage explains the 93.4 IFEval and 74.5 IFBench scores. Both show reasoning tuning did not break controllability.
CLR: Scaling at Test Time, Not Parameter Count
Claim-Level Reliability Assessment (CLR) is the report’s test-time scaling method. It runs on answer-verifiable tasks and adds no parameters.
The procedure has two steps. The model first generates K = 32 trajectories per problem. From each, it extracts M = 5 decision-relevant claims plus a final answer.
The model then acts as its own verifier. It validates or falsifies each claim, producing binary verdicts. CLR maps these into a nonlinear trajectory reliability score, where one weak claim sharply lowers the weight.
Answers are clustered by equivalence, and the highest reliability-weighted answer wins. The full flow runs 8 times, and the averaged Pass@1 is reported. CLR lifts AIME26 to 97.1 and BruMO25 to 99.2.
The interactive demo below lets you flip claims and watch the score collapse. It also lets you switch benchmarks and compare against larger models.