
Knowledge distillation (KD) transfers “dark knowledge” from a large teacher model to a smaller student. The student learns from the teacher’s full output probability distribution over tokens, not just correct answers. This is done via per-position Kullback–Leibler (KL) divergence over next-token probability distributions.
This formulation requires a shared tokenizer. A practitioner committed to Llama-3.2-1B cannot leverage stronger teachers with incompatible tokenizers — such as Phi-4-mini or Qwen3-4B — because token positions do not correspond across vocabularies. This also prevents multi-teacher distillation across tokenizer families.
NVIDIA researchers introduced X-Token, a logit-distribution-based method for cross-tokenizer KD (Knowledge distillation). It operates as a drop-in replacement for the standard KD loss, requiring no auxiliary trainable components and no architectural changes.
The Problem X-Token is Solving
Two prior approaches dominate cross-tokenizer KD. ULD (Universal Logit Distillation) sidesteps vocabulary alignment by rank-sorting both distributions and minimizing L1 distance. It discards token identity entirely. GOLD adds span alignment and a hybrid loss. It partitions tokens into a 1-to-1 string-matched common subset, trained with KL divergence, and an uncommon remainder, trained with ULD-style rank matching. GOLD is the current state of the art.
The research team identifies two structural failures in GOLD’s design:
Failure 1: Uncommon-token failure– When tokenizers fragment text differently, critical tokens fall into the unmatched uncommon subset. Llama-3 packs multi-digit numbers as single tokens — “201” is one token. Qwen3 splits them digit by digit: “2”, “0”, “1”. Under GOLD, all 1,100 of Llama’s two- and three-digit numerals (100 two-digit, 1,000 three-digit) fall into the uncommon set when Qwen3-4B is the teacher. Those tokens receive two types of harmful signal: identity-agnostic noise from rank-based ULD matching, and suppressive gradients from the common-KL term acting through the full-vocabulary softmax. The result: GSM8k accuracy drops to 2.56 under GOLD with Qwen3-4B, compared to 12.89 for same-tokenizer KD from a weaker Llama-3.2-3B teacher.
Failure 2: Over-conservative matching– GOLD uses strict string equality to define the common subset. A student token Hundreds corresponds to teacher tokens Hund followed by reds under teacher-side re-tokenization, but strict matching discards this pair. Useful alignment signal is lost even when the correspondence is well-formed.
These two failures require opposite remedies: eliminate the partition when critical tokens are misaligned, and relax it when alignment is structurally sound.
How X-Token Works
X-Token has three components: span alignment, a projection matrix W, and two complementary loss formulations — P-KL and H-KL.
Span Alignment
Teacher and student tokenizers produce sequences of different lengths for the same text. X-Token uses dynamic-programming (DP) span alignment, grouping tokens into chunks where each chunk-pair decodes to the same underlying text substring. A chain-rule merge then combines per-token probabilities within each chunk into a single chunk-level distribution for use in the distillation loss. The alignment is cached per sequence and adds no per-step training overhead.
The research team also identifies a failure in TRL’s surface-substring alignment, which is used in TRL’s GOLD trainer. TRL accumulates per-side decoded buffers and flushes only when both buffers match as equal raw strings. A byte-level disagreement — such as Llama-3 auto-prepending <bos> while Qwen-3 does not — prevents future flushes and forces all remaining tokens into one mis-grouped super-group at end of sequence. The DP approach handles this with a single gap move, regardless of sequence length.
The Projection Matrix W
After alignment, teacher and student distributions still operate over different vocabularies. The projection matrix W ∈ ℝVS|×|VT| maps each student token to a weighted combination of teacher tokens, bridging the vocabulary mismatch.
W is constructed deterministically in two passes:
Pass 1 (exact-match): For every (student token, teacher token) pair whose decoded strings match after canonicalization, set W[s, t] = 1. Canonicalization unifies space prefixes (Ġ, _, ␣), newlines, byte-fallback tokens of the form <0xHH>, and model-specific special tokens across tokenizer families.
Pass 2 (multi-token rule): For each student token without an exact match, re-tokenize its decoded text under the teacher tokenizer. If the resulting sequence has length ≤ 4, assign exponentially-decayed weights: W[s, τᵢ] = β·γⁱ with (β, γ) = (0.9, 0.1). A length-2 span receives normalized weights (0.909, 0.091). A length-3 span receives (0.9009, 0.0901, 0.0090). A length-4 span receives (0.9000, 0.0900, 0.0090, 0.0009). The leading sub-token receives the highest weight because it typically carries the most informative probability mass — for example, “_inter” in [“_inter”, “national”] or “_20” in [“_20”, “24”].
Each row is truncated to its top-4 entries and row-normalized. Because each row of W is non-negative and sums to 1, left-multiplication by W⊤ is probability-preserving: if pS is a probability vector, W⊤pS is also a valid probability vector over VT. W is constructed once before training and can optionally be jointly refined with the student under P-KL.
P-KL: Addressing Erroneous and Suppressive Gradients
P-KL removes the partition entirely. It projects the student distribution p̂S(k) into teacher vocabulary space via W:
p~S(k)[t]=∑s∈𝒱SW[s,t]⋅p^S(k)[s]tilde{p}_S^{(k)}[t] = sum_{sinmathcal{V}_S} W[s, t] cdot hat{p}_S^{(k)}[s]
Then it computes KL divergence directly between teacher and projected student:
∂ℒcommon∂zj=pS[j]⋅M𝒞(T)frac{partialmathcal{L}_{common}}{partial z_{j}} = p_S[j] cdot M_{mathcal{C}}(T)
There is no uncommon set, so rank-based ULD noise is eliminated. The suppressive gradient problem is also eliminated: the projection routes the student’s probability mass for “201” directly onto {2, 0, 1} in the teacher vocabulary via W.
The research team formally proves (Proposition 1) that GOLD’s common-KL term induces non-negative gradients on every uncommon student logit. The gradient on an uncommon student logit j is: ∂ℒcommon/∂zj = pS[j] · MC(T), where MC(T), is the teacher probability mass on the common subset. Under gradient descent, this always drives zj downward — suppressing every uncommon token’s probability regardless of the ground-truth token.
H-KL: Relaxing the 1-to-1 Matching
H-KL applies when the partition is structurally sound — that is, when critical tokens land in the common subset. In that case, GOLD’s direct KL on identity-aligned pairs delivers sharper per-pair supervision than P-KL’s projection, which blends student probability mass across multiple teacher tokens. The opportunity is to make the partition less wasteful by relaxing the strict string-equality criterion.
H-KL retains GOLD’s hybrid loss structure but expands the common set C using W. For each student token s, it selects the top-ranked teacher token t* = argmax_{t’∈V_T} W[s, t’], and adds (s, t*) to C. Exact matches are preserved since they receive weight 1 in W, the highest possible. Near-equivalent pairs like (Hundreds, Hund) — excluded by GOLD — are now admitted. The expanded C feeds the same hybrid loss: direct KL on common pairs, ULD on the remainder.
Selecting Between P-KL and H-KL
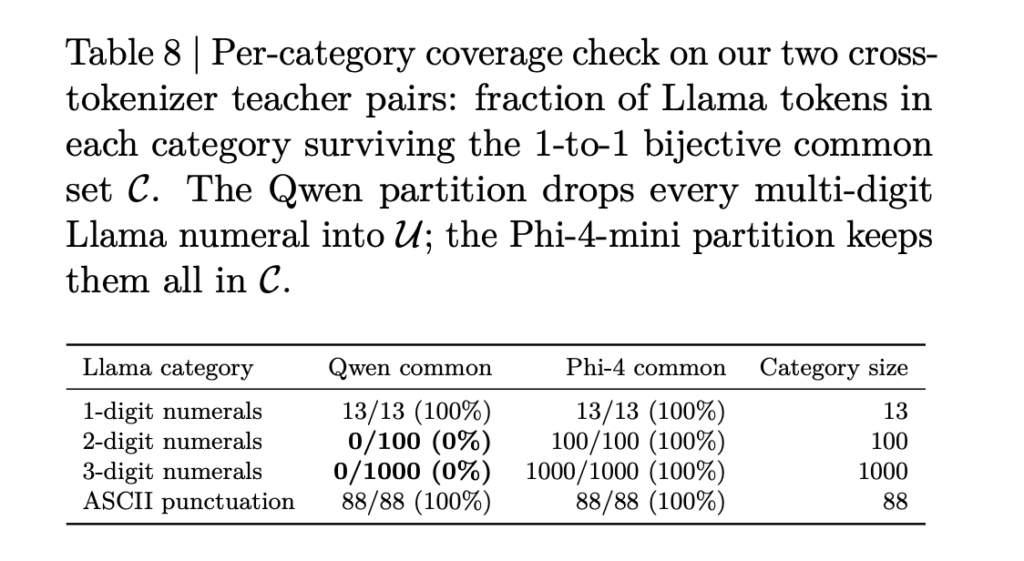
The selection uses a coverage audit over token categories in the student vocabulary. For math tasks, multi-digit numerals are the critical category. Table 8 in the research paper shows: under Qwen3-4B, 0 out of 100 two-digit Llama numerals and 0 out of 1,000 three-digit Llama numerals appear in C. Under Phi-4-mini-Instruct, all 100 two-digit and all 1,000 three-digit numerals appear in C. ASCII punctuation and single-digit numerals are fully covered in both cases.
https://arxiv.org/pdf/2605.21699
The rule: use P-KL when critical tokens fall outside C (Qwen3-4B), and H-KL when the partition is sound (Phi-4-mini-Instruct). Table 2 in the research paper shows the mode reversal is sharp: P-KL outperforms H-KL by +3.55 avg. on Qwen3-4B, while H-KL outperforms P-KL by +1.68 avg. on Phi-4-mini.
https://arxiv.org/pdf/2605.21699
Multi-Teacher Distillation
X-Token extends to multiple teachers. Each teacher has its own projection matrix W_m and loss selection. For same-tokenizer teachers, standard token-level KL is used. The multi-teacher loss aggregates per-teacher losses with weights αm:
ℒKD,multi=∑m=1Mαm1|𝒦m|∑k∈𝒦mℒ∗,m(k)mathcal{L}_{KD,multi} = sum_{m=1}^{M}alpha_{m}frac{1}{|mathcal{K}_{m}|}sum_{kinmathcal{K}_{m}}mathcal{L}_{*,m}^{(k)}
The research team evaluates static and confidence-adaptive weighting schemes. Confidence-adaptive variants compute α_m from cross-entropy, Shannon entropy, or maximum predicted probability of the teacher’s distribution. Static weighting outperforms adaptive schemes in both multi-teacher setups evaluated.
https://arxiv.org/pdf/2605.21699
Dynamic KD/CE Scaling
Training combines the distillation loss ℒKD with next-token cross-entropy ℒCE. Because these terms differ in magnitude and shift during training, X-Token rescales the KD term at each step to match the scale of ℒCE:
ℒ=sg(ℒCE/ℒKD)⋅ℒKD+ℒCEmathcal{L} = text{sg}(mathcal{L}_{CE} / mathcal{L}_{KD}) cdot mathcal{L}_{KD} + mathcal{L}_{CE}
where sg(·) is stop-gradient. Table 4 in the paper shows dynamic scaling outperforms three fixed-weight settings (KD-heavy, balanced, CE-heavy) on the Qwen3-4B (P-KL) pair.
https://arxiv.org/pdf/2605.21699
Experiments and Results
Student: Llama-3.2-1B. Teachers: Llama-3.2-3B (same tokenizer), Qwen3-4B, and Phi-4-mini-Instruct. Training data: NemotronClimbMix dataset, 30,000 steps, batch size 768, context length 4096. Optimizer: AdamW, learning rate 5×10⁻⁵, 5% warmup with cosine decay, weight decay 0.1, gradient clipping 1.0. Each experiment is feasible on a single NVIDIA H100 GPU; the research team used 128 H100s to speed up iteration.
Evaluation: 3-shot accuracy on MMLU, GSM8k, MATH-Hendrycks, Winogrande, and HellaSwag.
Key results:
SettingMethodAvg.No distillationLlama-1B (base)33.96No distillationContinued pre-training36.63Same tokenizerLlama-3B → 1B (KL)38.40Cross-tokenizerQwen-4B, ULD36.77Cross-tokenizerQwen-4B, GOLD35.03Cross-tokenizerQwen-4B, X-Token (P-KL)38.85Cross-tokenizerPhi-mini, ULD38.31Cross-tokenizerPhi-mini, GOLD38.66Cross-tokenizerPhi-mini, X-Token (H-KL)39.18Multi-teacherPhi-mini + Llama-3B (X-Token)40.48
On Qwen-4B (P-KL regime): GOLD reaches 35.03 avg., below even continued pre-training without a teacher (36.63). This confirms the partition is actively harmful when critical tokens are misaligned. Pure ULD (36.77) already improves over GOLD, indicating the partition is the primary failure source. P-KL further improves to 38.85 avg. (+3.82 over GOLD). GSM8k alone moves from 2.56 to 15.54, surpassing same-tokenizer KD from Llama-3.2-3B (12.89) on that benchmark.
On Phi-mini (H-KL regime): GOLD reaches 38.66 avg. — a reasonable baseline where the partition is structurally sound. H-KL improves to 39.18 avg. (+0.52 over GOLD). P-KL applied to Phi-mini drops to 37.50 avg., confirming that the wrong loss mode hurts even when W is available.
Multi-teacher: Phi-mini (H-KL, α=0.8) + Llama-3B (standard KL, α=0.2) under static weighting reaches 40.48 avg. This is +2.08 over same-family KD from Llama-3B alone, and +1.30 over the best single cross-tokenizer result (39.18). Combining Phi-mini + Qwen-4B — two teachers with overlapping reasoning strengths — scores only 38.49, below the best single teacher. Adding Qwen-4B as a third teacher yields 40.15, with math/reasoning degrading (GSM8k 20.39 → 19.18) while commonsense improves slightly. Teacher complementarity, not teacher count, drives gains.
Strengths and What to Watch
Strengths:
The suppressive gradient problem in GOLD’s hybrid loss is formally proved (Proposition 1), not just observed empirically
W is constructed rule-based from tokenizer strings alone; no training data or learned parameters needed at initialization
Dynamic KD/CE scaling removes the need to tune fixed loss weights; it outperforms three fixed-weight baselines in ablations
Multi-teacher extension adds no architectural changes; each teacher uses its own W_m and appropriate loss
The coverage audit for P-KL vs H-KL selection is a defined, reproducible criterion based on per-category token retention in C
What to Watch:
Experiments use only Llama-3.2-1B as the student under continued pre-training; larger students and instruction-tuned settings are not evaluated
Only three teacher pairs are tested; low-overlap tokenizer families (SentencePiece, byte-level BPE) are left for future work
Static weighting outperforms confidence-adaptive weighting in all tested multi-teacher setups, but why?
The multi-token rule in Pass 2 skips student tokens whose decoded text re-tokenizes to sequences longer than 4 under the teacher; those rows remain zero in W
Marktechpost’s Visual Explainer
#xtoken-slider-root*{box-sizing:border-box!important;margin:0!important;padding:0!important;font-family:’IBM Plex Mono’,’Courier New’,monospace!important;}
#xtoken-slider-root{background:#0a0a0a!important;border:1px solid #76B900!important;border-radius:6px!important;overflow:hidden!important;width:100%!important;max-width:780px!important;margin:0 auto!important;position:relative!important;}
#xtoken-slider-root hr,#xtoken-slider-root p:empty,#xtoken-slider-root del,#xtoken-slider-root s{display:none!important;}
/* Header */
#xtoken-slider-root .xt-header{background:#0a0a0a!important;border-bottom:2px solid #76B900!important;padding:14px 20px!important;display:flex!important;align-items:center!important;justify-content:space-between!important;}
#xtoken-slider-root .xt-logo{font-size:11px!important;color:#76B900!important;letter-spacing:3px!important;text-transform:uppercase!important;font-weight:700!important;}
#xtoken-slider-root .xt-counter{font-size:11px!important;color:#555!important;letter-spacing:1px!important;}
/* Slides */
#xtoken-slider-root .xt-track{position:relative!important;}
#xtoken-slider-root .xt-slide{display:none!important;padding:28px 24px 24px!important;min-height:340px!important;flex-direction:column!important;justify-content:flex-start!important;}
#xtoken-slider-root .xt-slide.active{display:flex!important;}
/* Slide label */
#xtoken-slider-root .xt-label{font-size:10px!important;color:#76B900!important;letter-spacing:3px!important;text-transform:uppercase!important;margin-bottom:10px!important;display:block!important;}
/* Slide title */
#xtoken-slider-root .xt-title{font-size:18px!important;color:#ffffff!important;line-height:1.35!important;margin-bottom:14px!important;font-family:’IBM Plex Mono’,’Courier New’,monospace!important;font-weight:700!important;}
/* Body text */
#xtoken-slider-root .xt-body{font-size:13px!important;color:#b0b0b0!important;line-height:1.75!important;font-family:’IBM Plex Mono’,’Courier New’,monospace!important;}
#xtoken-slider-root .xt-body p{margin-bottom:10px!important;display:block!important;}
#xtoken-slider-root .xt-body strong{color:#e8e8e8!important;font-weight:700!important;}
#xtoken-slider-root .xt-body em{color:#76B900!important;font-style:normal!important;}
/* Code pill */
#xtoken-slider-root .xt-code{display:inline-block!important;background:#1a1a1a!important;border:1px solid #333!important;border-radius:3px!important;padding:1px 7px!important;font-size:12px!important;color:#76B900!important;font-family:’IBM Plex Mono’,’Courier New’,monospace!important;}
/* Stat row */
#xtoken-slider-root .xt-stats{display:flex!important;gap:10px!important;margin-top:16px!important;flex-wrap:wrap!important;}
#xtoken-slider-root .xt-stat{background:#111!important;border:1px solid #2a2a2a!important;border-left:3px solid #76B900!important;border-radius:4px!important;padding:10px 14px!important;flex:1!important;min-width:130px!important;}
#xtoken-slider-root .xt-stat-val{font-size:20px!important;color:#76B900!important;font-weight:700!important;display:block!important;line-height:1!important;margin-bottom:4px!important;}
#xtoken-slider-root .xt-stat-lbl{font-size:10px!important;color:#666!important;letter-spacing:1px!important;text-transform:uppercase!important;display:block!important;}
/* Table */
#xtoken-slider-root .xt-table{width:100%!important;border-collapse:collapse!important;margin-top:14px!important;font-size:12px!important;}
#xtoken-slider-root .xt-table th{background:#111!important;color:#76B900!important;padding:7px 10px!important;text-align:left!important;font-weight:700!important;border-bottom:1px solid #2a2a2a!important;font-size:10px!important;letter-spacing:1px!important;text-transform:uppercase!important;}
#xtoken-slider-root .xt-table td{padding:7px 10px!important;border-bottom:1px solid #1a1a1a!important;color:#aaa!important;vertical-align:middle!important;}
#xtoken-slider-root .xt-table tr:last-child td{border-bottom:none!important;}
#xtoken-slider-root .xt-table .xt-best{color:#76B900!important;font-weight:700!important;}
#xtoken-slider-root .xt-table .xt-bad{color:#e05252!important;}
/* Badge */
#xtoken-slider-root .xt-badge{display:inline-block!important;background:#76B900!important;color:#000!important;font-size:10px!important;font-weight:700!important;padding:2px 8px!important;border-radius:2px!important;letter-spacing:1px!important;text-transform:uppercase!important;margin-right:6px!important;}
#xtoken-slider-root .xt-badge-red{background:#e05252!important;color:#fff!important;}
/* Step line */
#xtoken-slider-root .xt-steps{margin-top:14px!important;}
#xtoken-slider-root .xt-step{display:flex!important;gap:12px!important;margin-bottom:12px!important;align-items:flex-start!important;}
#xtoken-slider-root .xt-step-num{background:#76B900!important;color:#000!important;font-size:11px!important;font-weight:700!important;width:22px!important;height:22px!important;border-radius:50%!important;display:flex!important;align-items:center!important;justify-content:center!important;flex-shrink:0!important;margin-top:1px!important;}
#xtoken-slider-root .xt-step-txt{font-size:12.5px!important;color:#aaa!important;line-height:1.65!important;}
#xtoken-slider-root .xt-step-txt strong{color:#e8e8e8!important;}
#xtoken-slider-root .xt-step-line{width:1px!important;background:#2a2a2a!important;margin-left:11px!important;height:10px!important;display:block!important;}
/* Navigation */
#xtoken-slider-root .xt-nav{display:flex!important;align-items:center!important;justify-content:space-between!important;padding:12px 20px!important;border-top:1px solid #1e1e1e!important;background:#0d0d0d!important;}
#xtoken-slider-root .xt-btn{background:transparent!important;border:1px solid #333!important;color:#888!important;padding:6px 16px!important;font-size:11px!important;letter-spacing:2px!important;text-transform:uppercase!important;cursor:pointer!important;border-radius:3px!important;font-family:’IBM Plex Mono’,’Courier New’,monospace!important;transition:all 0.2s!important;}
#xtoken-slider-root .xt-btn:hover{border-color:#76B900!important;color:#76B900!important;}
#xtoken-slider-root .xt-btn:disabled{opacity:0.25!important;cursor:default!important;}
#xtoken-slider-root .xt-dots{display:flex!important;gap:6px!important;align-items:center!important;}
#xtoken-slider-root .xt-dot{width:6px!important;height:6px!important;border-radius:50%!important;background:#2a2a2a!important;cursor:pointer!important;border:none!important;padding:0!important;transition:background 0.2s!important;}
#xtoken-slider-root .xt-dot.active{background:#76B900!important;width:18px!important;border-radius:3px!important;}
/* Footer */
#xtoken-slider-root .xt-footer{background:#070707!important;padding:8px 20px!important;font-size:10px!important;color:#444!important;letter-spacing:1px!important;border-top:1px solid #1a1a1a!important;}
@media(max-width:640px){
#xtoken-slider-root .xt-title{font-size:15px!important;}
#xtoken-slider-root .xt-slide{padding:20px 16px 18px!important;min-height:auto!important;}
#xtoken-slider-root .xt-stats{flex-direction:column!important;}
#xtoken-slider-root .xt-stat{min-width:unset!important;}
#xtoken-slider-root .xt-table{font-size:11px!important;}
#xtoken-slider-root .xt-table th,#xtoken-slider-root .xt-table td{padding:6px 7px!important;}
#xtoken-slider-root .xt-nav{padding:10px 14px!important;}
}
■ X-Token — NVIDIA Research
1 / 8
01 — Background
What is Knowledge Distillation?
Knowledge distillation (KD) transfers “dark knowledge” from a large teacher model to a smaller student model. The student learns from the teacher’s full next-token probability distribution, not just the correct answer.
This is done via per-position KL divergence over the teacher’s output distribution at every token position in the sequence.
The constraint: standard KD requires a shared tokenizer. If Llama-3.2-1B is the student, it cannot learn from Qwen3-4B or Phi-4-mini — their token vocabularies do not align. Token positions have no correspondence across different tokenizer families.
Llama
Student tokenizer
Qwen / Phi
Incompatible teachers
≠ Match
Vocab mismatch
02 — The Problem
Two Structural Failures in GOLD
GOLD is the prior state-of-the-art cross-tokenizer KD method. It partitions tokens into a string-matched common subset (trained with KL) and an uncommon remainder (trained with ULD rank-matching).
NVIDIA researchers identified two distinct failures:
1
Uncommon-token failure: Critical tokens fall into the unmatched subset. Llama packs “201” as one token. Qwen splits it into “2”, “0”, “1”. All 1,100 multi-digit Llama numerals fall into the uncommon set under Qwen3-4B. They receive identity-agnostic noise and suppressive gradients — GSM8k drops to 2.56.
2
Over-conservative matching: Strict string equality discards well-formed pairs. Student token Hundreds maps to teacher tokens Hund + reds, but GOLD drops this alignment entirely.
03 — Solution
X-Token: Three Core Components
X-Token is a logit-distribution-based cross-tokenizer KD method. It requires no auxiliary trainable components and no architectural changes — it is a drop-in replacement for the standard KD loss.
1
Span Alignment: DP-based alignment groups tokens into chunks that decode to the same text substring. Cached per sequence — zero per-step overhead.
2
Projection Matrix W: A sparse matrix W ∈ ℝ⁼|V_S|×|V_T|⁽ maps each student token to a weighted combination of teacher tokens, bridging the vocabulary gap.
3
Two Loss Modes: P-KL removes the partition entirely. H-KL retains the partition but relaxes matching via top-1 mappings under W. Each targets a different failure mode.
04 — Projection Matrix W
How W is Constructed
W is built deterministically before training in two passes. No training data or learned parameters are required at initialization.
1
Exact-match pass: For every (student, teacher) token pair whose decoded strings match after canonicalization, set W[s,t] = 1. Canonicalization unifies space prefixes, newlines, byte-fallback tokens, and special tokens across families.
2
Multi-token rule pass: For unmatched student tokens, re-tokenize their decoded text under the teacher. Assign decayed weights W[s,τᵢ] = β·γⁱ with (β,γ) = (0.9, 0.1). A 2-token span gets (0.909, 0.091). Each row is truncated to top-4 entries and row-normalized.
Because each row sums to 1, Wᵀ is probability-preserving: Wᵀp_S is a valid probability vector over V_T without additional normalization.
05 — Loss Formulations
P-KL vs H-KL: When to Use Each
Selection is based on a coverage audit: measure what fraction of critical token categories (e.g. multi-digit numerals) appear in the common set C.
Property
P-KL
H-KL
Partition
Removed entirely
Retained, relaxed
Matching
Full vocab via W
Top-1 under W
Use when
Critical tokens fall outside C
Partition is sound
Teacher example
Qwen3-4B
Phi-4-mini-Instruct
Avg. gain vs GOLD
+3.82
+0.52
Applying the wrong mode reverses results: P-KL on Phi-mini drops to 37.50 avg. vs H-KL’s 39.18.
06 — Results
Benchmark Results on Llama-3.2-1B (3-shot)
Student: Llama-3.2-1B — trained on NemotronClimbMix, 30K steps, batch 768, context 4096.
Method
GSM8k
Avg.
Llama-1B (base)
5.69
33.96
Continued pre-training
10.25
36.63
Same-tokenizer KD (Llama-3B)
12.89
38.40
Qwen-4B, GOLD
2.56
35.03
Qwen-4B, X-Token (P-KL)
15.54
38.85
Phi-mini, GOLD
16.50
38.66
Phi-mini, X-Token (H-KL)
19.11
39.18
Phi-mini + Llama-3B (Multi)
20.39
40.48
07 — Multi-Teacher Distillation
Teacher Complementarity Drives Gains
X-Token extends to multiple teachers. Each gets its own projection matrix W_m and loss mode. The aggregated loss uses per-teacher weights α_m.
Key finding: static weighting outperforms confidence-adaptive weighting in all tested setups. Phi-mini (α=0.8) + Llama-3B (α=0.2) achieves the best result.
Teacher Combination
Avg.
Note
Phi-mini only (H-KL)
39.18
Best single
Phi-mini + Llama-3B
40.48
Complementary
Phi-mini + Qwen-4B
38.49
Overlapping
Phi-mini + Qwen-4B + Llama-3B
40.15
3rd teacher hurts math
Combining two reasoning-heavy teachers (Phi-mini + Qwen-4B) scores below the best single teacher. Teacher diversity matters more than teacher count.
08 — Key Takeaways
What to Remember About X-Token
1
GOLD’s partition actively harms training when critical tokens (e.g., multi-digit numerals) fall into the uncommon set — P-KL eliminates the partition entirely using projection matrix W.
2
H-KL retains the partition but relaxes matching to top-1 mappings under W — best when the partition is structurally sound.
3
The projection matrix W is built rule-based before training from tokenizer strings alone; no learned parameters required at init.
4
Multi-teacher gains (+1.3 over single-teacher) come from teacher complementarity, not from adding more teachers with overlapping strengths.
5
GSM8k recovers from 2.56 (GOLD) to 15.54 (P-KL) — a 6× gain that exceeds same-tokenizer KD from a stronger Llama-3.2-3B teacher.
arXiv: 2605.21699 — Institution: NVIDIA
← Prev
Next →
NVIDIA Research — X-Token: Projection-Guided Cross-Tokenizer Knowledge Distillation — arXiv:2605.21699 — marktechpost.com
(function(){
var cur=0,total=8;
var slides=document.querySelectorAll(‘#xtoken-slider-root .xt-slide’);
var dotsEl=document.getElementById(‘xt-dots’);
var counter=document.getElementById(‘xt-counter’);
var dots=[];
for(var i=0;i=0&&n